Datenbanken
Ein relationales Datenmodell implementieren (Version: 31. Januar 2022)
1.1 Die Motivation
1.2 Datenbank-Grundlagen
DB-Entwurf Teil-A
2.1 ERD: Die Komponenten
2.2 ERD: Kardinalität
2.3 ERD: Beziehungstypen
2.4 Primär- und Fremdschlüssel
2.5 Die Umsetzung der 1:1-Beziehung
2.6 Die Umsetzung der 1:mc-Beziehung
2.7 Die Umsetzung der mc:mc-Beziehung
2.8 Zusammengesetzter Primärschlüssel
2.9 Tabellenbeschreibung
2.10 Eintrag erzwingen → NOT NULL Constraint
2.11 Einmaligkeit erzwingen → UNIQUE Constraint
2.12 Referentielle Integrität
3.1 Normalisierung von Relationen
3.2 Normalisierungsprozess → Normalform 1 bis 3
3.3 Rekursive Beziehungen
3.4 Generalisierung/Spezialisierung
4. DB-Transaktionen
4.1 SQL - Structured Query Language
4.2 Mit SQL Tabellen erzeugen & bearbeiten
4.3 Mit SQL Tabellen abfragen
4.4 Mit SQL Tabellen verknüpfen
5. Abfragen und Formulare erstellen
5.1 Abfragen in LibreOffice-Base
5.2 Formulare in LibreOffice-Base
6. Test und Dokumentation
1. Einführung
1.1 Die Motivation
Ein Tabellen-Negativbeispiel: Wenn wir für eine Problemstellung eine einzige grosse Tabelle erstellen, sind viele Informationen mehrfach vorhanden.
Dieses mehrfache Abspeichern der gleichen Information nennt man Redundanz. Redundante Daten sind fehleranfällig.
Bei Änderungen oder Löschungen werden eventuell nicht alle Einträge berücksichtigt oder unterschiedlich geändert.
In Datenbanken sollten daher keine redundanten Informationen abgespeichert werden. Um dieses Ziel zu erreichen, werden die
Informationen auf mehrere Tabellen verteilt und über Beziehungen (Relationen) miteinander verbunden.
 Zur Erinnerung: Eine Tabelle ist eine Beschreibung eines bestimmten Objektes unserer realen Welt.
Zusammengehörende Daten, die sich auf ein bestimmtes einzelnes Objekt beziehen, werden als eine Zeile in der Tabelle gespeichert.
Eine Tabelle ist in senkrechte und waagrechte Spalten unterteilt. Die Schnittfläche die sich durch Überschneidung einer senkrechten Spalte mit einer waagrechten Zeile ergibt, wird als Feld oder Zelle bezeichnet.
Nur Felder können Werte enthalten.
Zur Erinnerung: Eine Tabelle ist eine Beschreibung eines bestimmten Objektes unserer realen Welt.
Zusammengehörende Daten, die sich auf ein bestimmtes einzelnes Objekt beziehen, werden als eine Zeile in der Tabelle gespeichert.
Eine Tabelle ist in senkrechte und waagrechte Spalten unterteilt. Die Schnittfläche die sich durch Überschneidung einer senkrechten Spalte mit einer waagrechten Zeile ergibt, wird als Feld oder Zelle bezeichnet.
Nur Felder können Werte enthalten.
- Entität (Tabellenname, Entitätstyp, Relationen zwischen Entitäten)
- Attribut (Spalte, Merkmal)
- Datensatz, Tupel (Zeile, n-Tupel)
- Attributwert (Datenfeld, Zelle)
1.2 Datenbank-Grundlagen
- Daten verarbeiten heisst:
- Daten erfassen
- Daten mutieren
- Daten löschen
- Daten auswerten
- Anforderungen an eine Datenbank: Zentraler Bestandteil in der Datenverarbeitung ist die Datenbank (DB).
An diese werden verschiedene Anforderungen gestellt, wie:
- Einfachen Zugriff auf die Daten, ohne Kenntnisse des inneren Aufbaus
- Flexibilität: Die Datenbank lässt sich mit vertretbarem Aufwand erweitern und ändern
- Datenschutz: Die Benutzer haben unterschiedliche Sichten auf die Daten und verschiedene Rechte bezüglich lesen, schreiben (einfügen und ändern) und löschen der Daten. Alle Benutzer haben eine gemeinsame Datenbasis
- Datensicherheit: Schutz vor Datenverlust oder Verfälschung durch Fehlmanipulation
- Datenkonsistenz/Redundanzfrei: In einer Datenbank dürfen alle Informationen über eine bestimmte Sache nur einmal vorkommen. Damit wird verhindert, dass widersprüchliche Informationen über eine Sache entstehen können
- Datenunabhängige Applikationen: Die Applikationen (Masken, Programme etc.) sind idealerweise unabhängig von den Daten. Das heisst, falls sich Daten ändern, müssen keine Änderungen an den Applikationen gemacht werden
- Datenbank-Modelle: Je nach Einsatzgebiet existieren verschiedene Datenbankmodelle:
- Hierarchische DB: Ältestes Datenbankkonzept / Beschränkt brauchbar weil nur 1:mc Beziehungen redundanzfrei realisierbar sind / Wenig flexibel, jedoch schnell in der Abfrage, da alle Daten sequentiell in einem einzigen File abgelegt sind / Veraltet.
- Netzwerkförmige DB: Basieren im Prinzip auf den hierarchischen DBs, lassen aber mc:mc Beziehungen zu / Wenig flexibel und veraltet.
- Relationale DB: Pro Themenkreis (Entitätsmenge) existiert ein File (Tabelle oder Relation) / Tabellen stehen in Beziehung zueinander / Beziehung werden mittels Identifikationsschlüsseln bzw. Fremdschlüsseln geschaffen. Auf dieser Seite wird nur die relationale DB bzw. deren Entwurf und Implementierung weiter verfolgt.
- Definition Datenbank: Eine Datenbank ist ein System zur Beschreibung, Speicherung und Wiedergewinnung von umfangreichen Datenmengen,
die von mehreren Anwendungsprogrammen (-gleichzeitig-) benutzt werden können. Sie besteht aus zwei Hauptteilen, den eigentlichen Daten und den Verwaltungsprogrammen
(Datenbank-Management-System, Datenbanksoftware), welche gemäss einer vorgegebenen Beschreibung Daten speichern, suchen, löschen oder ändern kann.
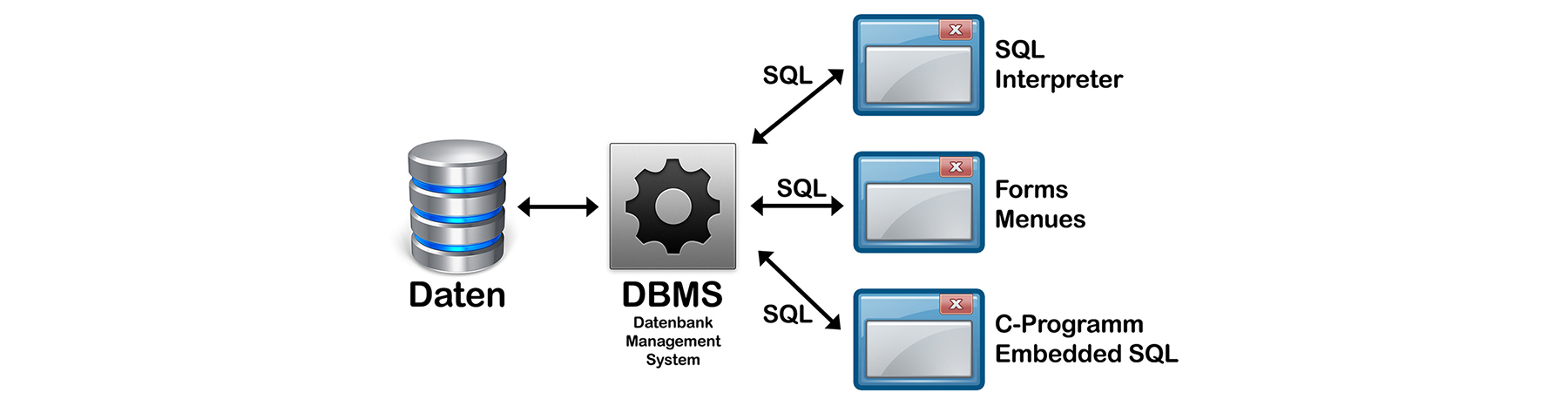
- Das Datenbank-Management-System (DBMS): Der Benutzer bzw. seine Applikation greift niemals direkt auf die Daten zu, sondern immer über ein Kontroll- und Verwaltungssystem.
Dieses heisst Datenbank-Management-System (DBMS). Die wesentlichen Funktionen eines DBMS sind:
- Speicherung, Überschreibung und Löschung von Daten
- Verwaltung der Metadaten
- Vorkehrungen zur Datensicherheit
- Vorkehrungen zum Datenschutz
- Vorkehrungen zur Datenintegrität
- Ermöglichung des Mehrbenutzerbetriebs durch das Transaktionskonzept
- Optimierung von Abfragen
- Ermöglichung von Triggern und Stored Procedures
- Bereitstellung von Kennzahlen über Technik und Betrieb des DBMS
- Designmethode: «Der Design bestimmt die Qualität der Applikation»
- Konzeptionelles Datenmodell: Diese höchste Abstraktionsebene ermöglicht es, die gesamte für eine Applikation relevante Information in einem datenbankunabhängigen Schema festzuhalten und verständlich darzustellen. (Entity-Relationship-Modell)
- Logisches Datenmodell: Abbildung des konzeptionellen Datenmodells auf einen bestimmten Datenbanktyp
- Integritätsbedingungen: Festhalten von Datentypen, Bedingungen zwischen Daten in Form von Regeln oder Prüfroutinen. (Datadictionary)
- Verwaltungssprache: «Die Sprache bestimmt die Funktionalität der Datenbank»
- Datendefinitionssprache DDL: Definition von Datenstrukturen, Datentypen und Integritätsbedingungen
- Datenmanipulationssprache DML: Einfügen, Ändern, Löschen und Abfragen einer Datenbank
- Datenkontrollsprache DCL: Regeln von Zugriffsrechten, Setzen von Systemparametern, Optimierung der physischen Organisation etc.
- Structured Query Language (SQL) beinhaltet: Datendefinitionssprache (DDL) UND Datenmanipulationssprache (DML)
- Physische Struktur: «Die physische Ebene bestimmt die Performance und Stabilität der Datenbank»
- Datenbanksystem (DBMS) nimmt Befehle und Anfragen in der Verwaltungssprache entgegen und stellt die eigentliche DB in Form von Speicherplatz auf Disk dar.
- Die Routinen führen Zugriff auf Daten durch und sorgen für sicheren fehlerfreien Betrieb.
- Bei Crash während einer Modifikation Zurücksetzen der DB in konsistenten Zustand.
- Begriffserklärungen:
- Datenintegrität: Jede Datensammlung wird innert kurzen Zeit unbrauchbar, wenn ihre Integrität nicht gewährleistet ist. Man betrachte dazu als Beispiel die Telefonbücher in öffentlichen Telefonkabinen. Da werden Seiten herausgerissen, gelegentlich Unflätigkeiten zu einzelnen Abonnentennamen hinzugefügt, während Nachträge von Neuabonnenten (begreiflicherweise) fehlen. Zum Glück gibt’s da noch den Auskunftsdienst. Von einer Datenbank erwarten wir somit nicht bloss schnelle Datenzugriffe und Flexibilität bei der Datenspeicherung, sondern auch Hilfe zur Abwehr unerwünschter Ereignisse.
- Concurrency Control: Die Art, wie das Datenbank-Managementsystem gleichzeitig laufende Transaktionen bedient. Der Hauptmechanismus des Concurrency-Control ist das Sperren von Daten (Locking)
- Data-Recovery: Wiederherstellen eines konsistenten DB-Zustandes (Konsistenz). Eine DB ist konsistent, wenn alle Daten der Realität entsprechen, alle relevanten Daten vollständig vorhanden und alle Integritätsbedingungen erfüllt sind. Wird ein konsistenter Zustand in einen anderen konsistenten Zustand überführt, so nennt man dies eine Transaktion.
- Praxisüberlegungen: Im folgenden einige Gesichtspunkte, die während der Datenbank-Pflichtenheftphase einer
Klärung bedarfen und die Wahl der Software entscheidend beeinflussen können:
- Wie kompliziert sind die Datenstrukturen
- Wie hoch ist die Anzahl Transaktionen pro Zeiteinheit und die Anzahl gleichzeitiger Benutzer
- Wie hoch ist der maximale Platzbedarf und mit welcher Geschwindigkeit wächst die Datenmenge
- Genügt die zu erwartende Performance der Spezifikation
- Wie häufig müssen die Daten gesichert werden
- Wie wichtig ist die Konsistenz der Daten
- Über welche Schnittstellen müssen die Daten zur Verfügung stehen
- Wieviel Aufwand muss für Datenschutz betrieben werden
- Müssen bestehende Daten in eine neue Applikation übernommen werden
- Welches sind geeignete Datenbankprodukte und wie hoch sind die Kosten für DBMS und seine Tools
- Konzeptioneller Datenbankentwurf: Datenorientierter Ansatz → Welche Daten müssen im System verwaltet werden?
Wie werden die Daten im System verändert?
 ∇ Datenbank-SW installieren
∇ Datenbank-SW installieren
2. DB-Entwurf Teil-A
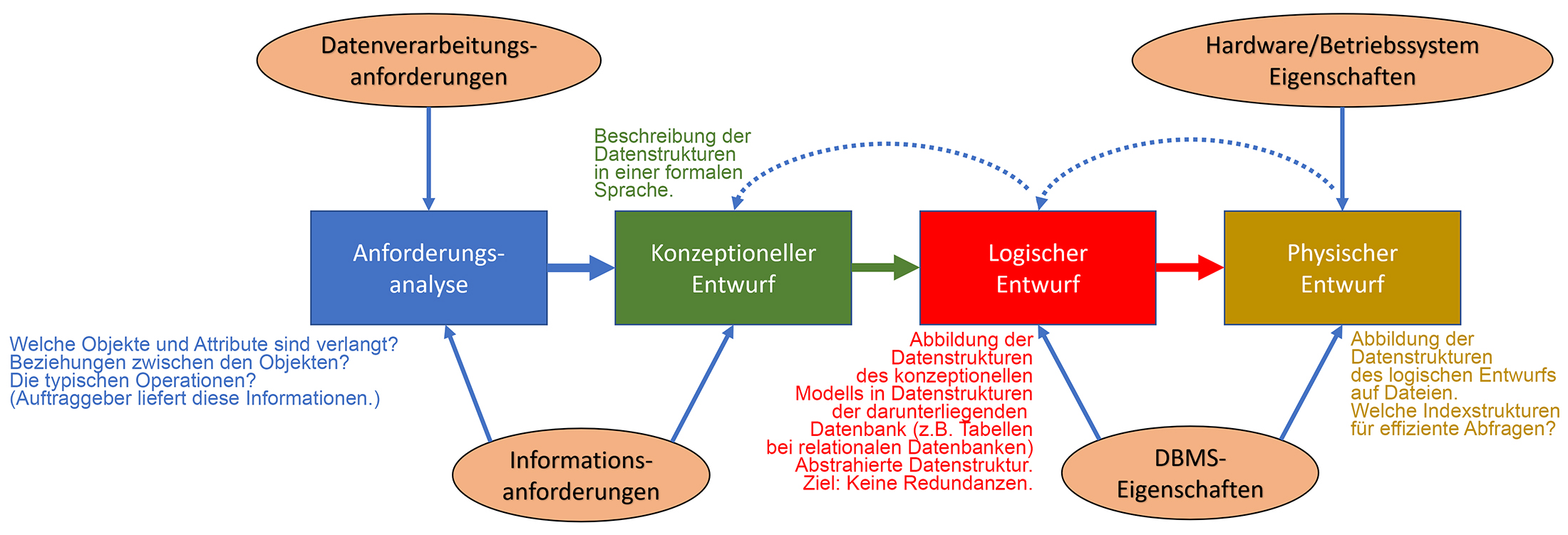
Der DB-Entwicklungsprozess verläuft grundsätzlich in 4 Phasen:
- Analyse: Dies beinhaltet das Studium des Pflichtenheftes, weitere Abklärungen beim Auftraggeber, Präzisierung der Anforderungen, Studium der abzubildenden Prozesse etc.
- Design: Nun folgt der Entwurf der Datenbank. In unserem Fall bedeutet dies die Erstellung eines der 3. Normalform genügenden Entity-Relationship-Diagramm (ERD) und den Tabellenbeschreibungen.
- Implementation: Erst jetzt werden in der gewählten DB die Tabellen aufgrund des ERD und den Tabellenbeschreibungen erstellt.
In dieser Phase entstehen auch die geforderten Abfragen und Eingabeformulare (Benutzerschnittstelle). - Testen: Wie jedes andere SW-Produkt muss auch die DB ausgiebig getestet werden. (Formelle Tests mit Testvorschrift und Testprotokollen)
ERM und ERD
Das Entity-Relationship-Modell (ERM) dient dazu, im Rahmen der semantischen Datenmodellierung einen in einem gegebenen Kontext
relevanten Ausschnitt der realen Welt zu beschreiben. Das ERM besteht aus einer grafischen Darstellung von Entitätstypen und Beziehungstypen, das Entitätenblockdiagramm bzw. Entity-Relationship-Diagramm (ERD) genannt wird,
und einer Beschreibung der darin verwendeten Elemente.
Beachten: Der Begriff Entity-Relationship-Diagramm wird im folgenden mit der Bezeichnung ERD abgekürzt.
2.1 ERD: Die Komponenten

- Entität (Entity) Individuell identifizierbares Objekt der Wirklichkeit; z. B. die Person Müller, das Fahrzeug XY etc.
- Beziehung (Relationship) Verknüpfung / Zusammenhang zwischen zwei oder mehreren Entitäten; z. B. Herr Müller fährt Fahrzeug XY oder im Umkehrschluss: Fahrzeug XY gehört Herrn Müller.
- Eigenschaft (Attribute) Was über eine Entität (im Kontext) von Interesse ist; z. B. der Wohnort von Herrn Müller
- Entitätstyp Typisierung gleichartiger Entitäten z. B. Angestellter, Projekt, Buch, Autor, Verlag
- Beziehungstyp (Relationship-Typ) Typisierung gleichartiger Beziehungen; z. B. Angestellter leitet Projekt
- Attribut Typisierung gleichartiger Eigenschaften, z. B. Nachname, Vorname und Eintrittsdatum für den Entitätstyp Angestellter. Das Attribut oder die Attributkombination, deren Wert(e) die Entität eindeutig beschreiben, d. h. diese identifizieren, heissen identifizierende(s) Attribut(e), zum Beispiel ist das Attribut Projektnummer identifizierend für den Entitätstyp Projekt.
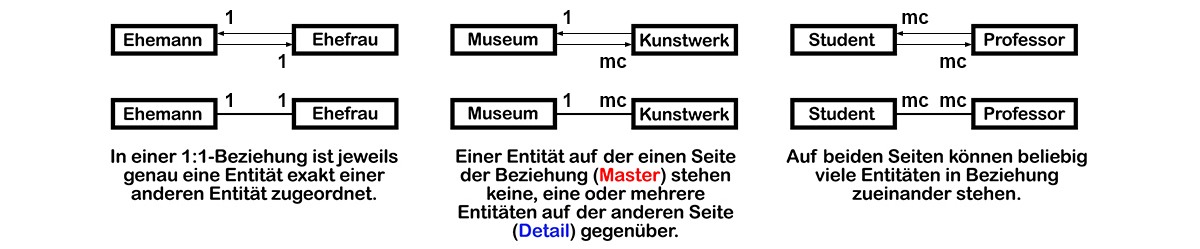
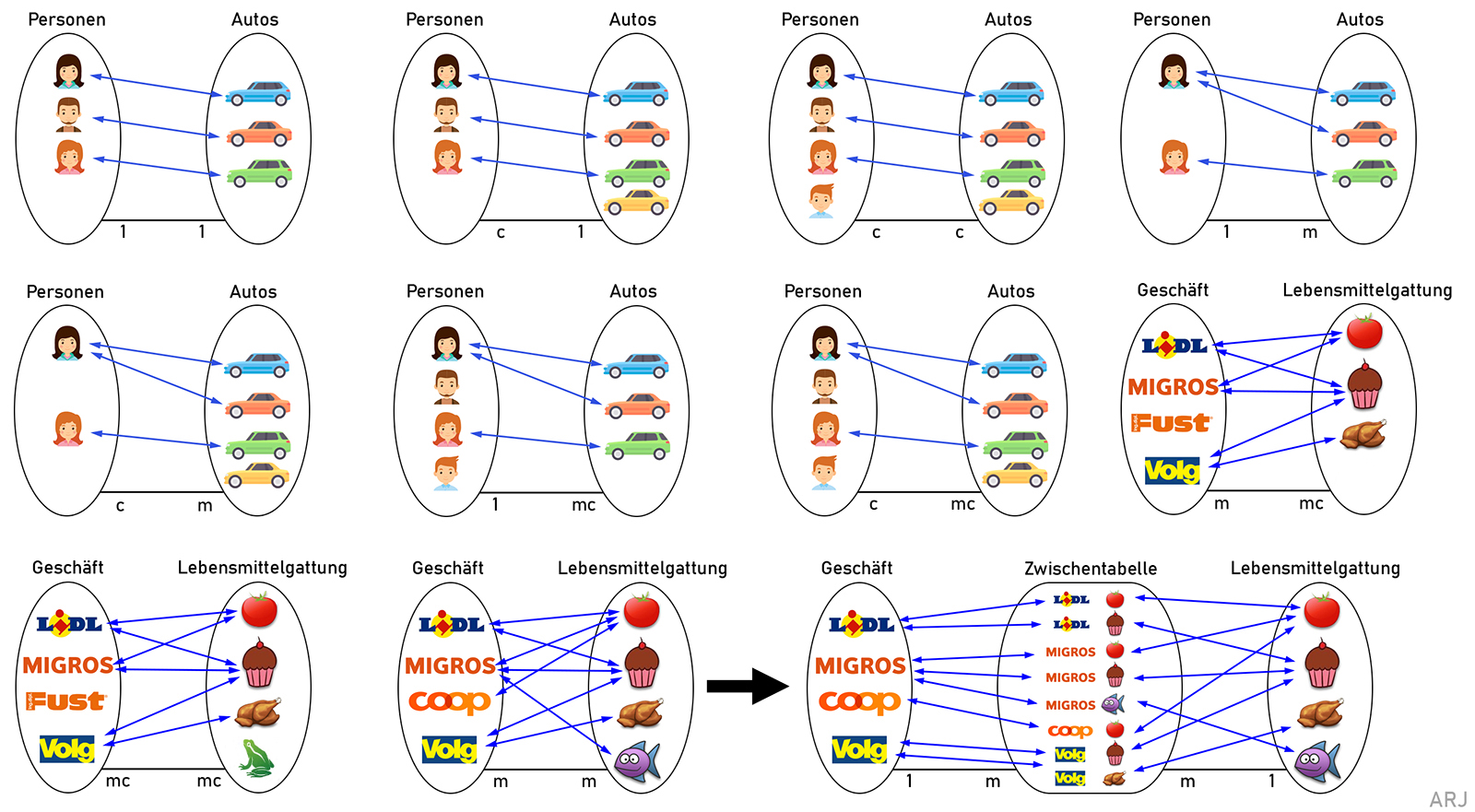
2.2 ERD: Kardinalität
Kardinalitäten sind Mengenangaben, mit denen in der Datenmodellierung für Entity-Relationship-Diagramme (ER-Diagramme) für jeden Beziehungstyp festgelegt wird,
wie viele Entitäten eines Entitätstyps mit genau einer Entität des anderen am Beziehungstyp beteiligten Entitätstyps (und umgekehrt)
in Beziehung stehen können oder müssen. Beispiele:
2.3 ERD: Beziehungstypen
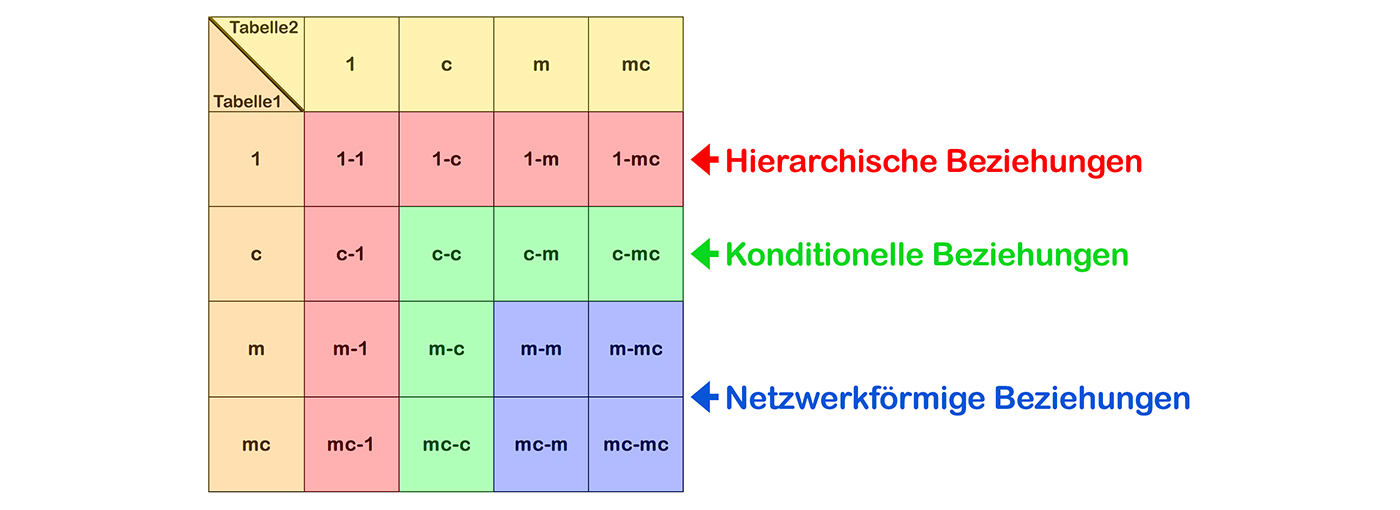 Wobei gilt:
Wobei gilt:
- 1 = Ein Datensatz aus Tabelle1 entspricht einem Datensatz aus Tabelle2
- c = Ein Datensatz aus Tabelle1 entspricht keinem oder genau einem Datensatz aus Tabelle2
- m = Ein Datensatz aus Tabelle1 entspricht mindestens einem Datensatz aus Tabelle2
- mc = Ein Datensatz aus Tabelle1 entspricht keinem oder beliebig vielen Datensätzen aus Tabelle2
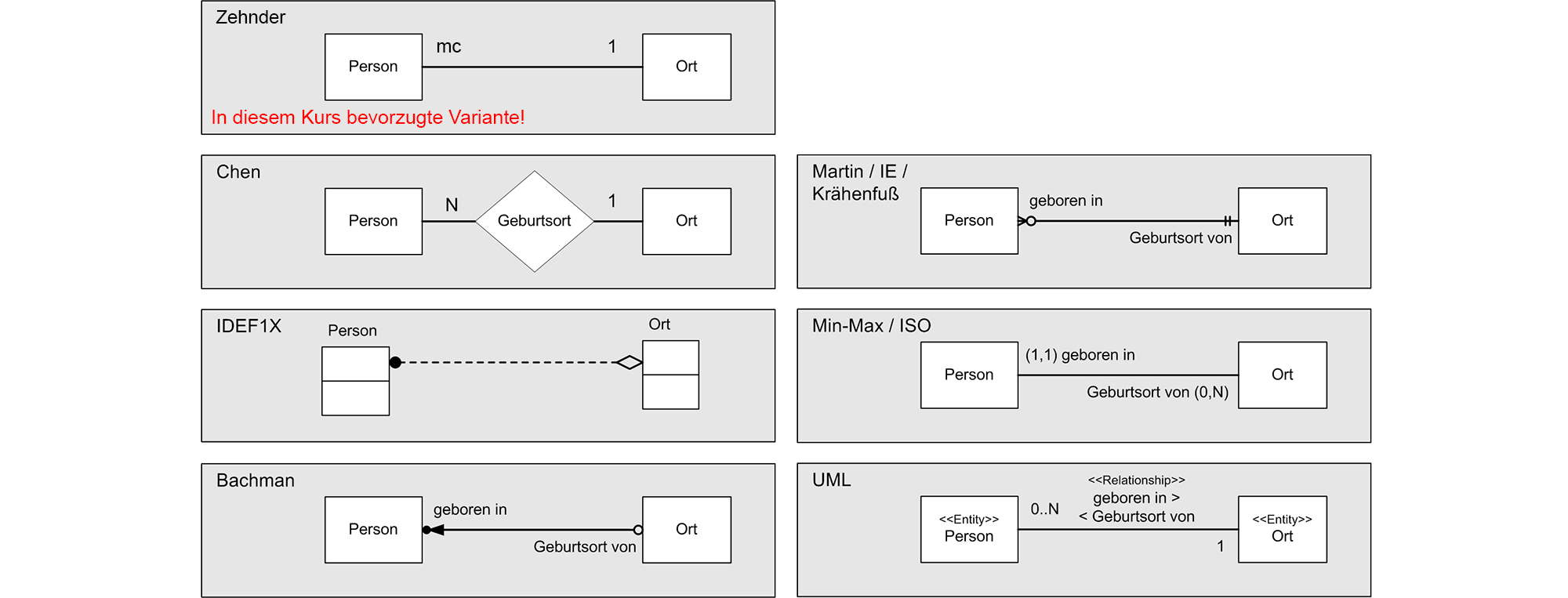
Verschiedene Notationen zur Darstellung von ERDs und Kardinalität:
Im Laufe der Zeit haben sich verschiedene Darstellungsformen etabliert, die auf ihre Art den folgenden Sachverhalt ausdrücken:
- Eine Person ist in einem (1) Ort geboren. Ein Ort ist Geburtsort von beliebig vielen (N) Personen.
- Ob jede Person auf einen Geburtsort verweisen muss (ggf. gäbe es den Ort "Unbekannt") und/oder ob es auch Orte geben kann, an denen gemäss Datenbestand keine Person geboren wurde, wird in der Chen-Notation nicht und bei den anderen Notationsformen mit unterschiedlichen Symbolen grafisch dargestellt.
 ∇ AUFGABEN
∇ AUFGABEN
∇ LÖSUNGEN
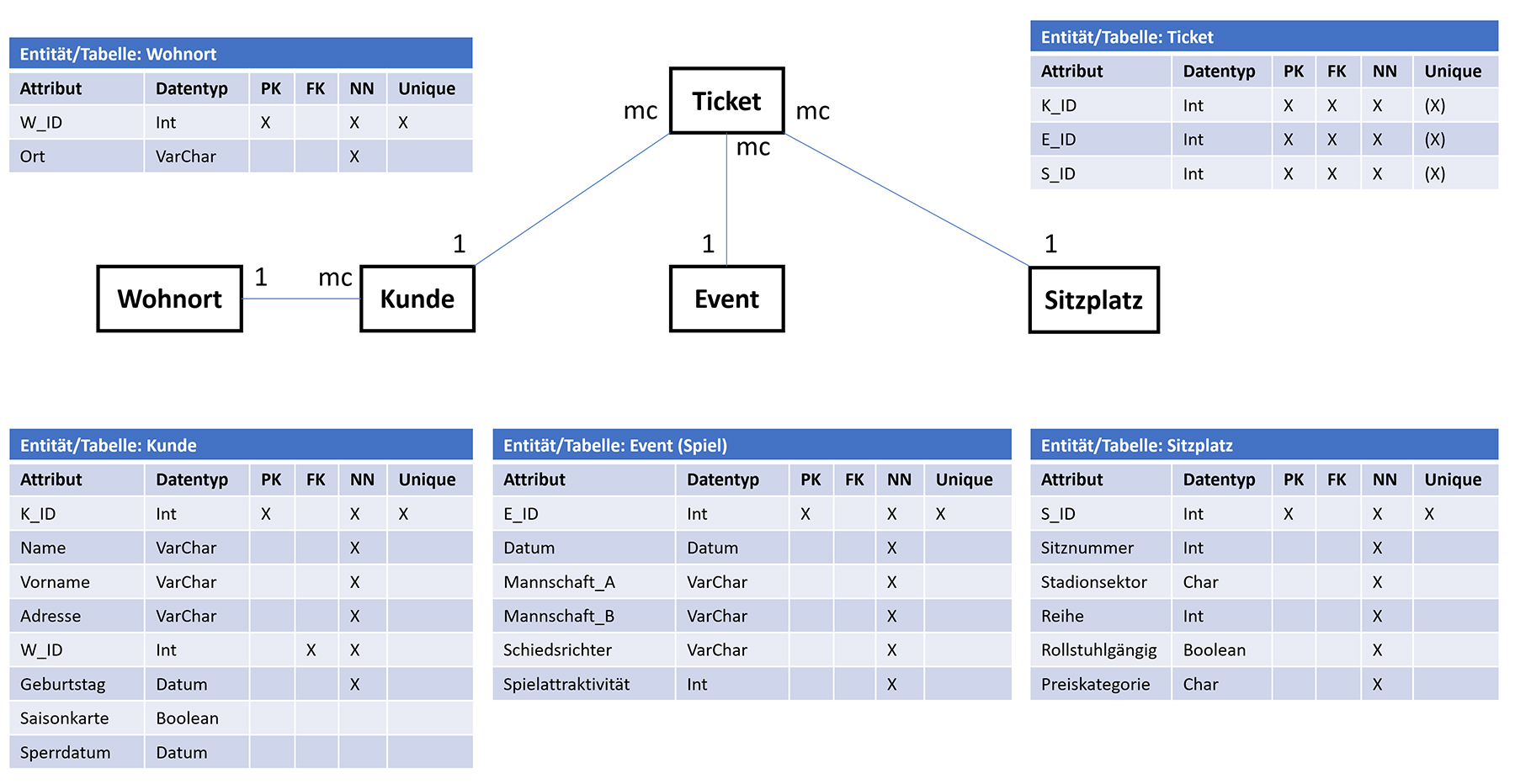
2.4 Primär- und Fremdschlüssel
- Primärschlüssel: Jede Zeile soll eindeutig identifiziert werden können. Oft wird dazu eine zusätzliche eingerichtete Spalte benutzt, deren Attributwerte keinerlei eigene Bedeutung besitzen und nur der Eindeutigkeit dienen. Diese Tabellenspalte wird als Primärschlüssel bezeichnet.
- Fremdschlüssel: Bei voneinander abhängigen Tabellen wird die Abhängigkeit häufig in Form einer Fremdschlüsselspalte in der untergeordneten Tabelle dargestellt. Dabei finden sich die Fremdschlüsselwerte in der Primärschlüsselspalte der übergeordneten Tabelle wieder und bilden somit die Beziehung zwischen Zeilen beider Tabellen ab.
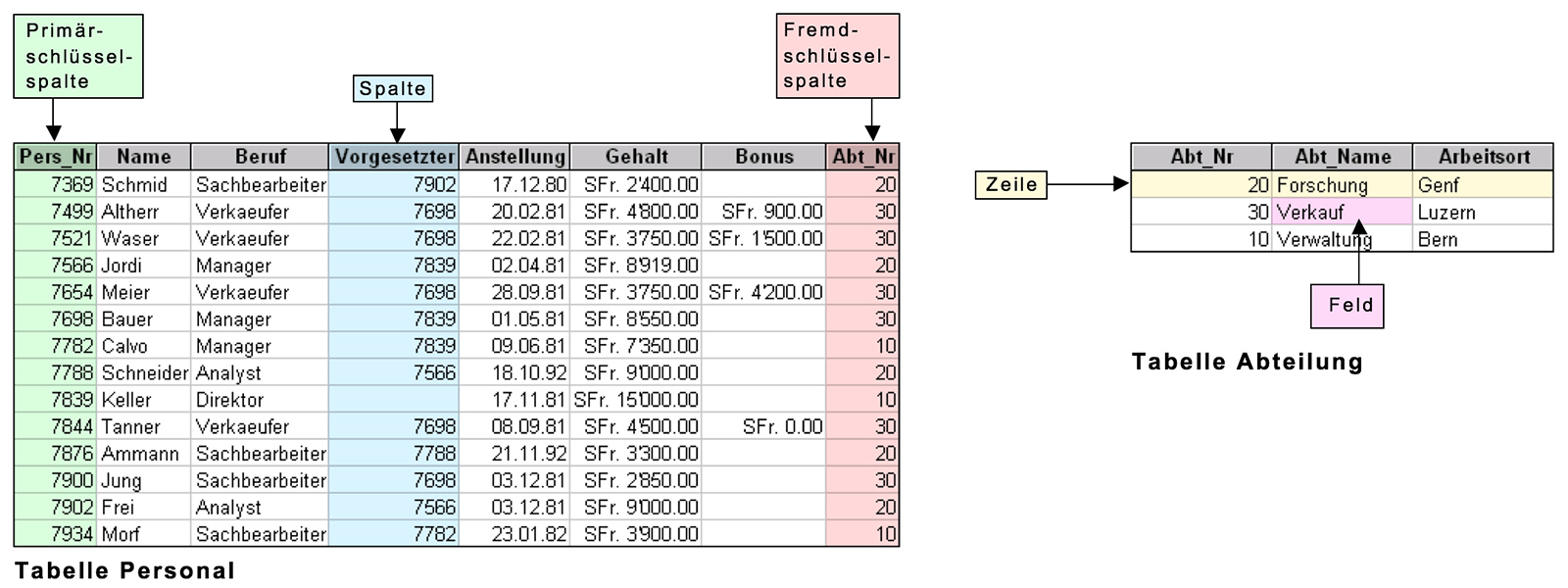 Zeile = Entität / Spalte = Attribut / Feld = Attributwert mit Domäne (Domäne:Datentyp und Wertebereich)
Zeile = Entität / Spalte = Attribut / Feld = Attributwert mit Domäne (Domäne:Datentyp und Wertebereich)(Hinweis zu dieser Tabelle: Die Spalte Vorgesetzter ist bereits ein Spezialfall. Die Personalnummern in dieser Kolonne zeigen auf Primärschlüssel in der eigenen Tabelle. Dies weil gewisse Person Mitarbeiter und auch Vorgesetzte sind. Dabei handelt es sich um eine rekursive Beziehung, die später behandelt wird.)
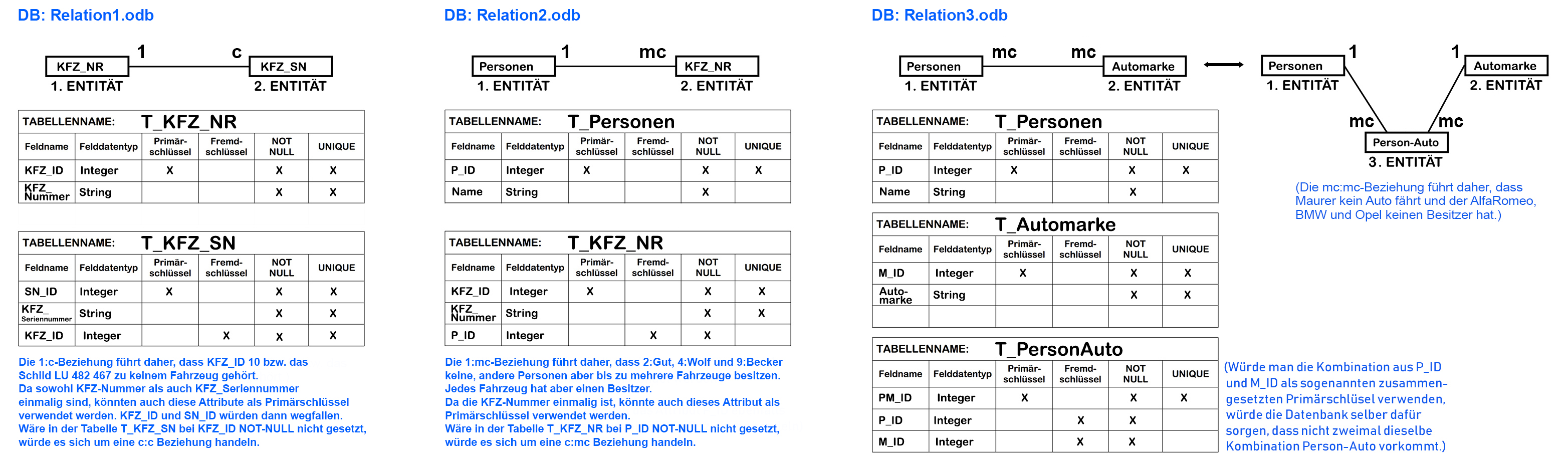
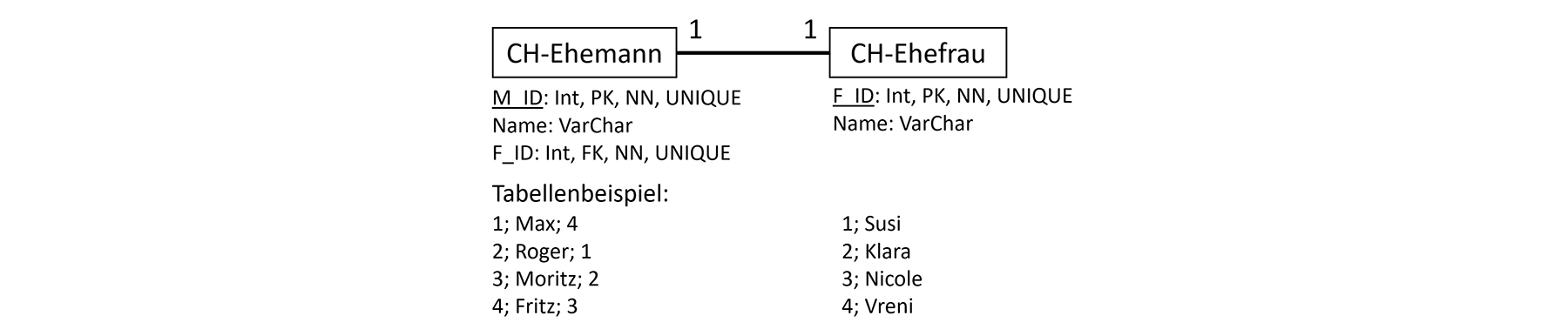
2.5 Die Umsetzung der 1:1-Beziehung
Hier wird der Primärschlüssel (PK) einer der beiden Tabellen als Fremdschlüssel (FK) der anderen Tabelle in eine zusätzliche Spalte aufgenommen.
Bei welcher der Tabellen das geschieht, ist technisch irrelevant. Praktisch versucht man die reale Abhängigkeit darzustellen,
indem man den Primärschlüssel der Master-Tabelle in eine zusätzliche Spalte der Detail-Tabelle aufnimmt. Zusätzlich muss sichergestellt werden,
dass die Werte in der Spalte mit dem Fremdschlüssel nur einmal vorkommen (z. B. durch Trigger, NOT-NULL (NN), UNIQUE-Constraints).
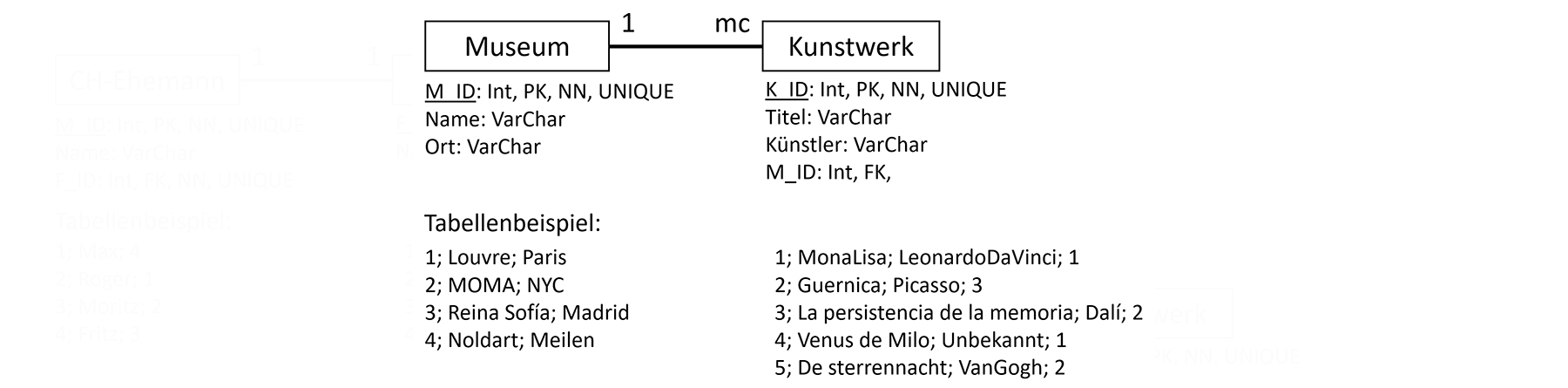
2.6 Die Umsetzung der 1:mc-Beziehung
Die Detail-Tabelle (Kunstwerk) erhält eine zusätzliche Spalte, die als Fremdschlüssel (FK) den Primärschlüssel (PK) der Master-Tabelle (Museum) aufnimmt.
Bei einer 1:mc-Beziehung nennt man das Attribut, das mehrere «Instanzen» haben kann, also jenes der mc-Seite «Mehrwertiges Attribut».
Sollte es sich um eine 1:m-Beziehung handeln, muss mit einem NOT-NULL-Constraint (NN) sichergestellt werden, dass ein Datensatz
aus Entität1 mindestens einem Datensatz aus Entität2 entspricht.
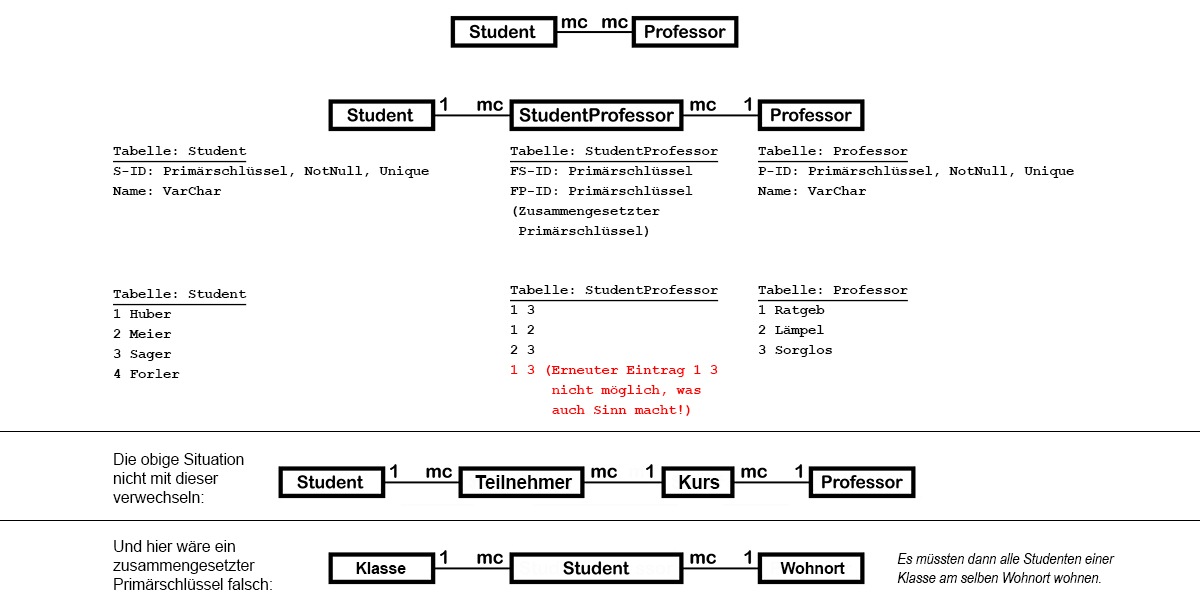
2.7 Die Umsetzung der mc:mc-Beziehung
mc:mc-Beziehungen (gilt auch für m:mc, m:m etc.) können in relationalen Datenbanken nicht direkt umgesetzt werden.
Zur Realisierung wird eine zusätzliche Tabelle erstellt, die die Primärschlüssel beider Tabellen als Fremdschlüssel enthält.
Die mc:mc-Beziehung wird also aufgelöst, und man erhält eine weitere Datenbanktabelle, die zwei 1:mc-Beziehungen realisiert.
Bei m:mc oder m:m-Beziehungen muss wiederum mit NOT-NULL-Constraints sichergestellt werden, dass ein Datensatz aus Entität1 mindestens einem Datensatz aus Entität2 entspricht.
Oft werden für die Bezeichnung der die mc:mc-Beziehung realisierenden Tabelle die Bezeichnungen der beiden daran beteiligten Tabellen verwendet;
bei den Tabellen «Student» und «Professor» könnte so die zusätzliche Tabelle «StudentProfessor» heissen.
 Gehören zur mc:mc-Beziehung weitere Attribute, so wird häufig bereits im ER-Modell ein eigener Entitätstyp gebildet, womit zwei getrennte 1:mc-Beziehungen entstehen.
Beispiel: Hotel ist reserviert für Person; neuer Entitätstyp «Reservierung» – mit mc:1-Beziehungen zu Person und Hotel und weiteren Attributen wie Reservierungszeitraum,
Reservierungsstatus etc.
Gehören zur mc:mc-Beziehung weitere Attribute, so wird häufig bereits im ER-Modell ein eigener Entitätstyp gebildet, womit zwei getrennte 1:mc-Beziehungen entstehen.
Beispiel: Hotel ist reserviert für Person; neuer Entitätstyp «Reservierung» – mit mc:1-Beziehungen zu Person und Hotel und weiteren Attributen wie Reservierungszeitraum,
Reservierungsstatus etc.
2.8 Zusammengesetzter Primärschlüssel
Zur Erinnerung: Um die Tupel (Zeilen, Records) in einer Relation (Tabelle) eindeutig identifizieren zu können,
wird für die Relation ein Primärschlüssel angegeben. Der Primärschlüssel kann sich auch aus mehreren Attributen zusammensetzen.
Bei Zwischentabellen aus n:m-Beziehungen kommt das immer vor. Das hat in dem Fall auch den Vorteil, wiederholtes Eintragen einer
Fremdschlüsselkombination zu verhindern, wie folgendes Beispiel zeigt:
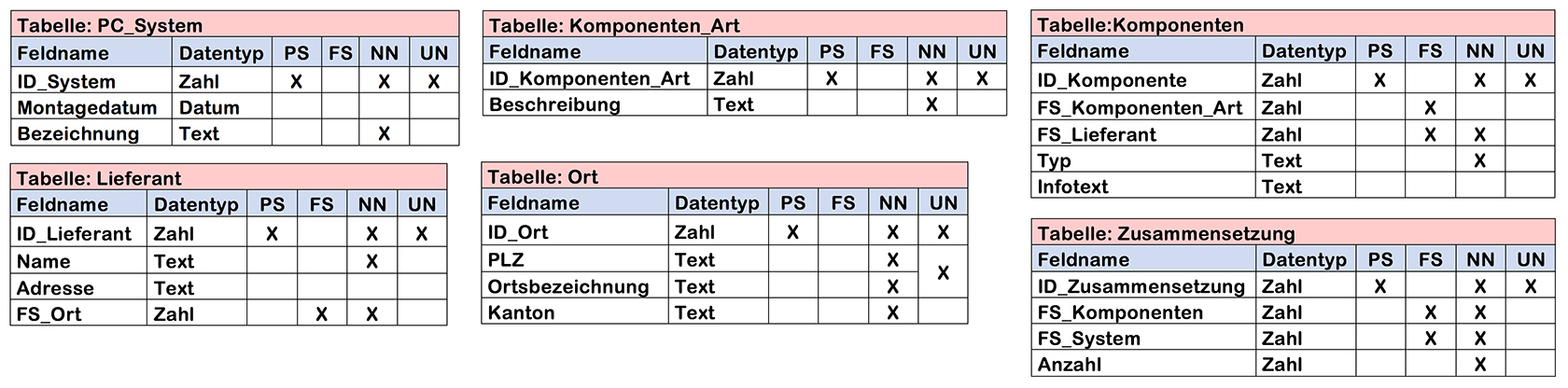
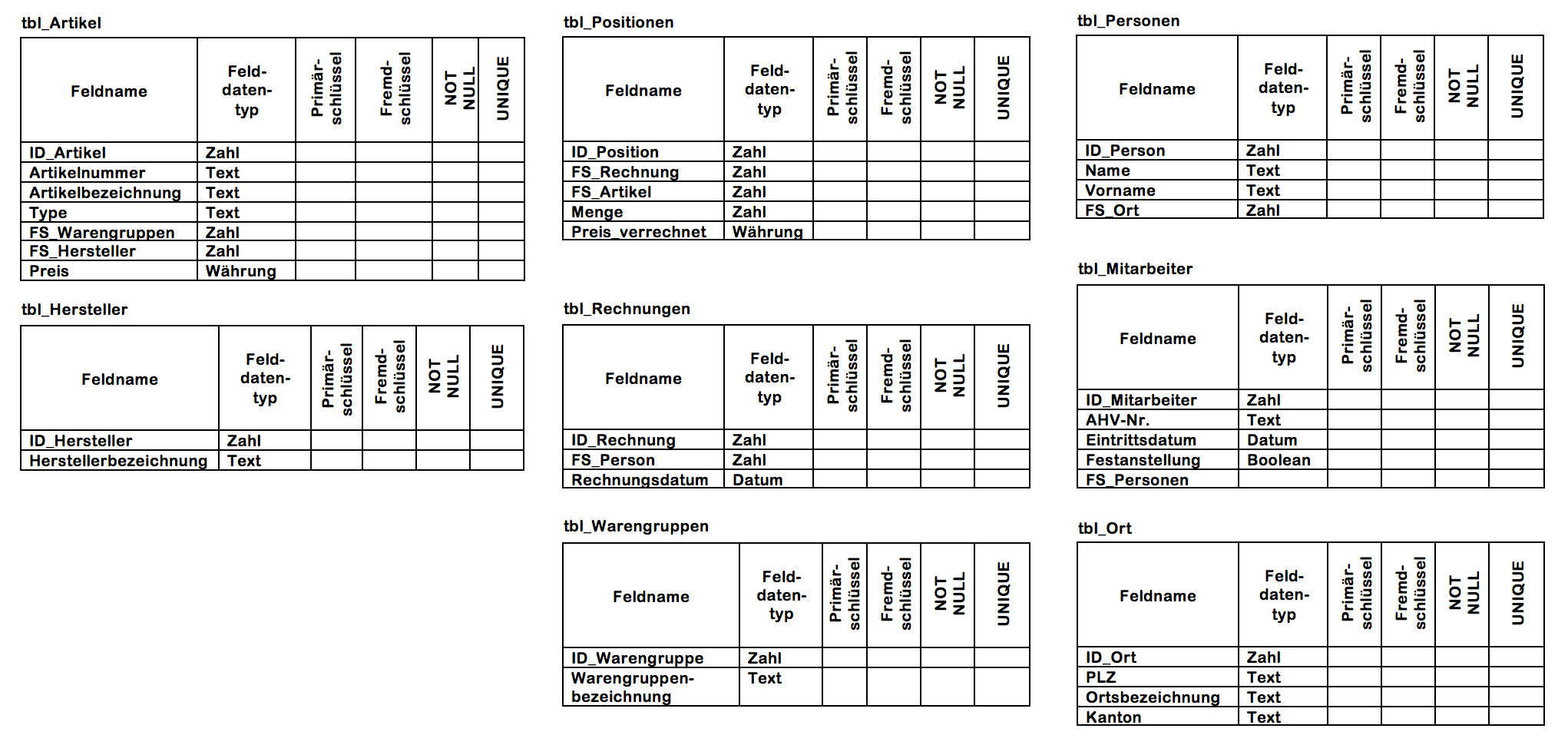
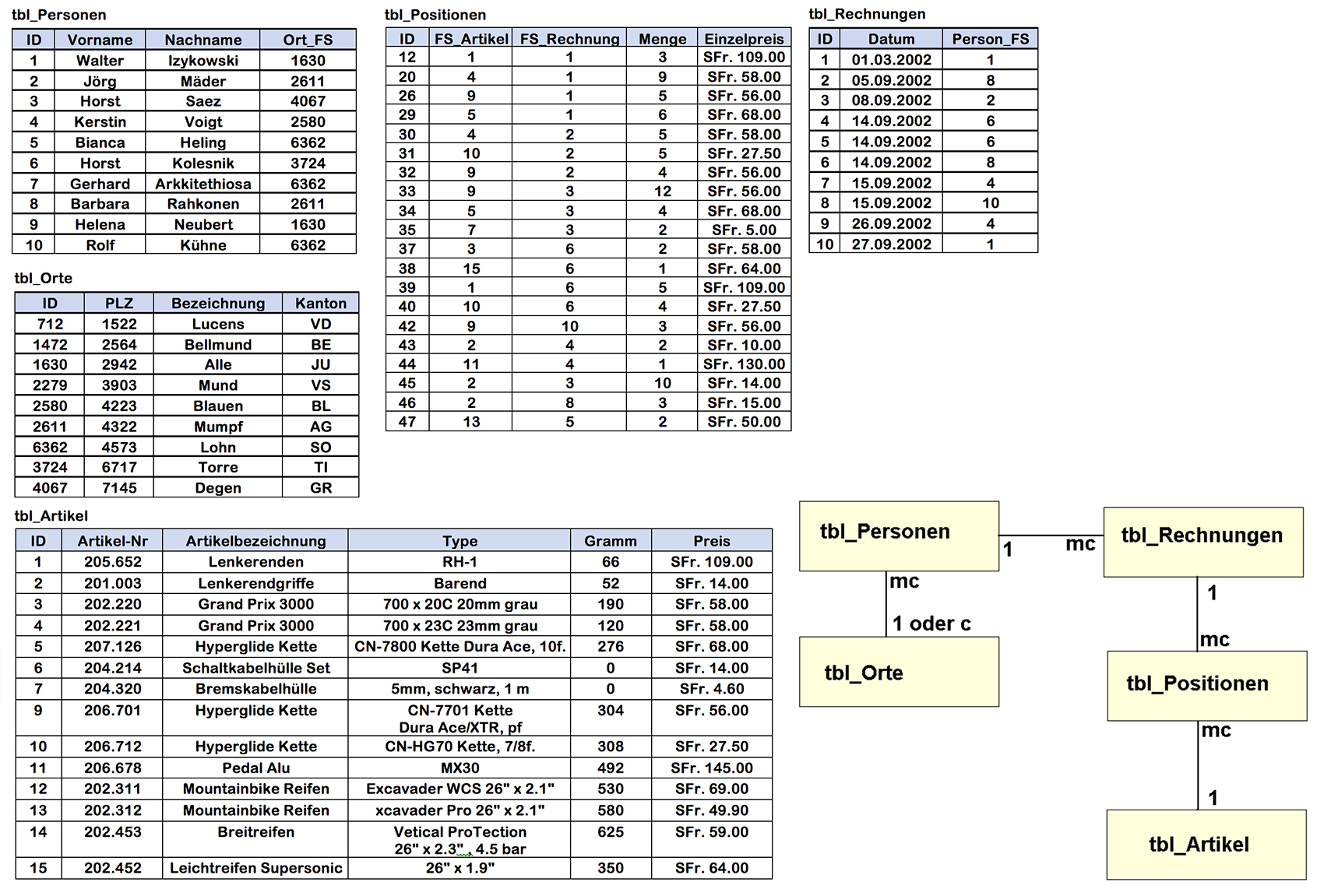
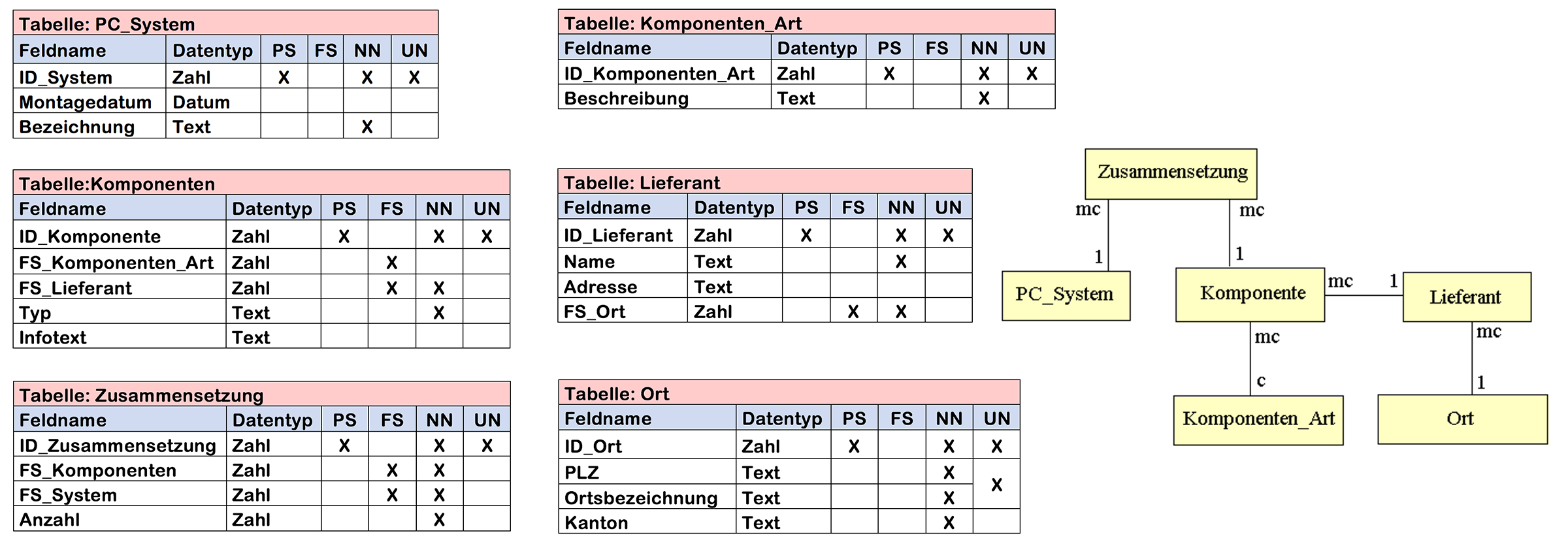
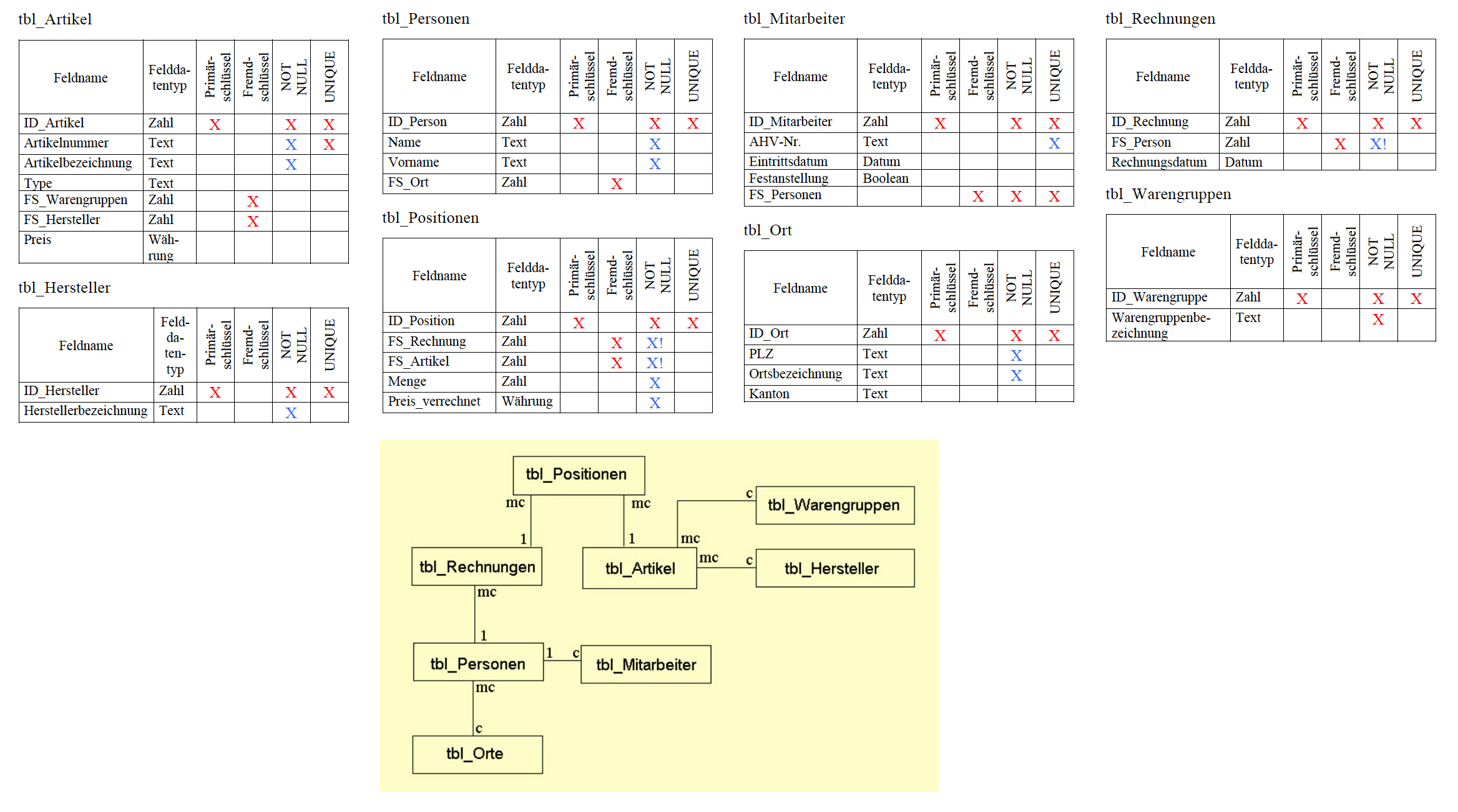
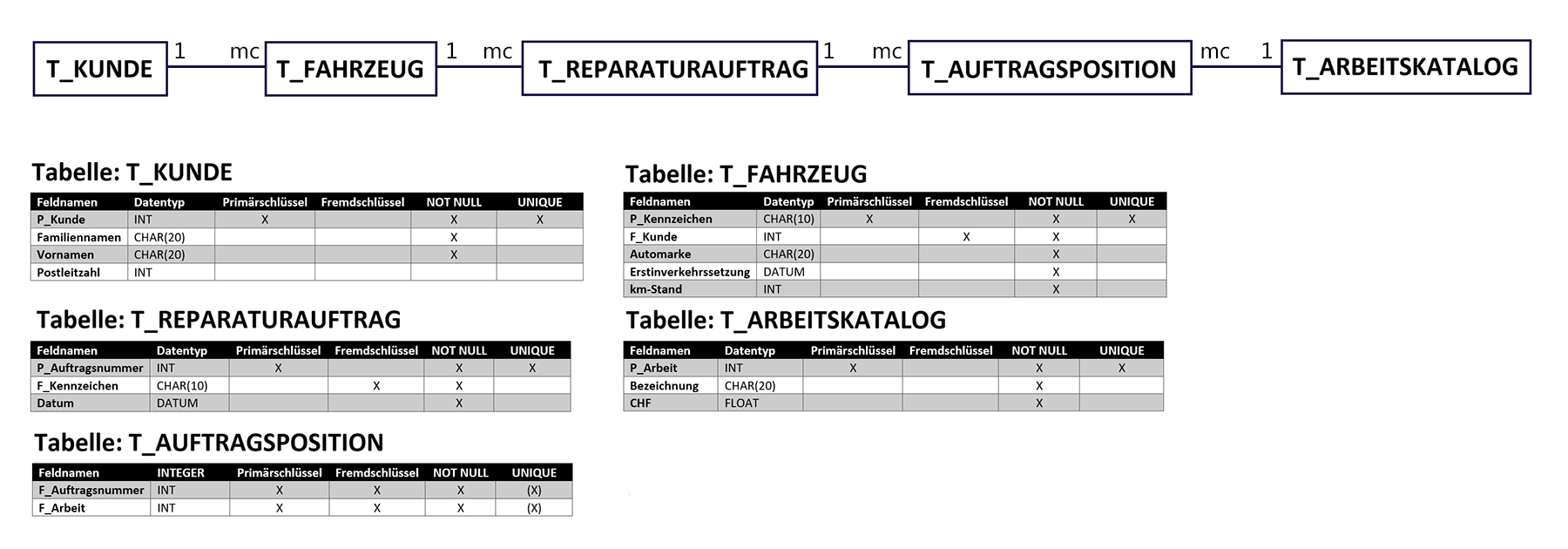
2.9 Tabellenbeschreibung
Ein wichtiger Teil der Systemdokumentation ist neben dem ERD die Tabellenbeschreibungen. Damit kann nun ein Datenbankentwickler Tabellen und Beziehungen erstellen. Die Tabellenbeschreibung gibt Auskunft über alle Attribute (Spalten), deren Datentyp, Primär- oder Fremdschlüsselfunktion, ob zwingend eine Eingabe erforderlich ist (NOT NULL) und die Eingabe einmalig (UNIQUE) sein muss.
- Beispiel einer Tabellenbeschreibung in Bildform:

- Beispiel einer Tabellenbeschreibung in Textform:
Entität: T_Person ID_Person : Integer, Primärschlüssel, NOT-NULL, UNIQUE Name : Text, NOT-Null Geburtsdatum : Datum, NOT-Null AHV-Nr : Text, NOT-NULL, UNIQUE MobilePhoneNr : Text ID_Ort : Integer, Fremdschlüssel, NOT-NULL
2.10 Eintrag erzwingen → NOT NULL Constraint
Darf ein Tabellenfeld nicht leer bleiben, wie z.B. beim Primärschlüssel, kann man die Eingabe bei der SQL-Datendefinition so erzwingen:
create table "adressen" ( Personalnummer int NOT NULL PRIMARY KEY, Name varchar(50) NOT NULL, Alter int );Im Tabellenbearbeitungsmodus von OpenOfficeBase kann in den Feldeigenschaften des entsprechenden Attributs durch die Wahl «Eingabe erforderlich → Ja» NOT-NULL-Verhalten bewirkt werden.2.11 Einmaligkeit erzwingen → UNIQUE Constraint
Oft wird verlangt, dass in einer Tabellenspalte jeder Wert nur einmal vorkommt.
Datenbanktechnisch formuliert: Der Skalar muss innerhalb des Attributes einzigartig sein.
Dies ist z.B. bei einem Primärschlüssel notwendig. Bei OOBase und auch Access ist das bei Primärschlüsseln automatisch der Fall. Anders sieht es aus, wenn ein weiteres Attribut einzigartig sein muss, wie z.B. in einer Tabelle «Fahrzeug», wo aus verständlichen Gründen die Nummer eines Fahrzeug-Kontrollschildes nur einmal vorkommen darf.
Bei Access ist es kein Problem, diesen Constraint zu ergänzen. Bei OOBase muss man das von Hand, bzw. mit einem SQL-Kommando im SQL-Editor erledigen. In OOBase findet man den SQL-Editor in der Menüleiste unter «Extras» → «SQL». Danach den SQL-Befehl bei «Auszuführendes Kommando» eingeben.ALTER TABLE "Fahrzeug" ADD UNIQUE ("Kontrollschild"); («Fahrzeug» ist der Tabellennamen und «Kontrollschild» das Attribut. Das Semikolon «;» am Zeilenende darf nicht vergessen werden.)Bei einer SQL-DB kann der Unique-Constraint bereits bei der Erstellung der Tabelle mitgegeben werden:create table adressen ( Personalnummer int NOT NULL UNIQUE, Name char(50), Vorname char(30), );
2.12 Referentielle Integrität
Um gemäss «Referentieller Integrität» bzw. «Beziehungsintegrität» Datenintegrität zu gewährleisten, dürfen Datensätze über ihre Fremdschlüssel nur auf existierende Datensätze verweisen. Das bedeutet:
- Ein neuer Datensatz mit einem Fremdschlüssel kann nur dann in die Tabelle eingefügt werden, wenn in der referenzierten Tabelle ein Datensatz mit entsprechendem Wert im Primärschlüssel bereits existiert.
- Eine Datensatzlöschung oder Änderung des Schlüssels in einem Primär-Datensatz ist nur dann möglich, wenn zu diesem Datensatz keine abhängigen Datensätze in Beziehung stehen.
- Änderungsweitergabe: Wenn der eindeutige Schlüssel eines Datensatzes geändert wird, kann das DBMS die Fremdschlüssel in allen abhängigen Datensätzen anpassen – anstatt die Änderung abzulehnen
- Löschweitergabe: Falls abhängige Datensätze bei Löschung des Masterdatensatzes mitzulöschen sind
- Kaskadierung: Lösch- oder Änderungsweitergabe, die mehrstufig wirkt
- Beziehung auf sich selbst: In bestimmten Situationen kann ein Detaildatensatz auch auf sich selbst verweisen
Beispiel zu referentieller Integrität
Dieses OpenOfficeBase-Beispiel zeigt den vereinfachten Zusammenhang zwischen Lehrer, Lernenden, Kurse und Tests auf:
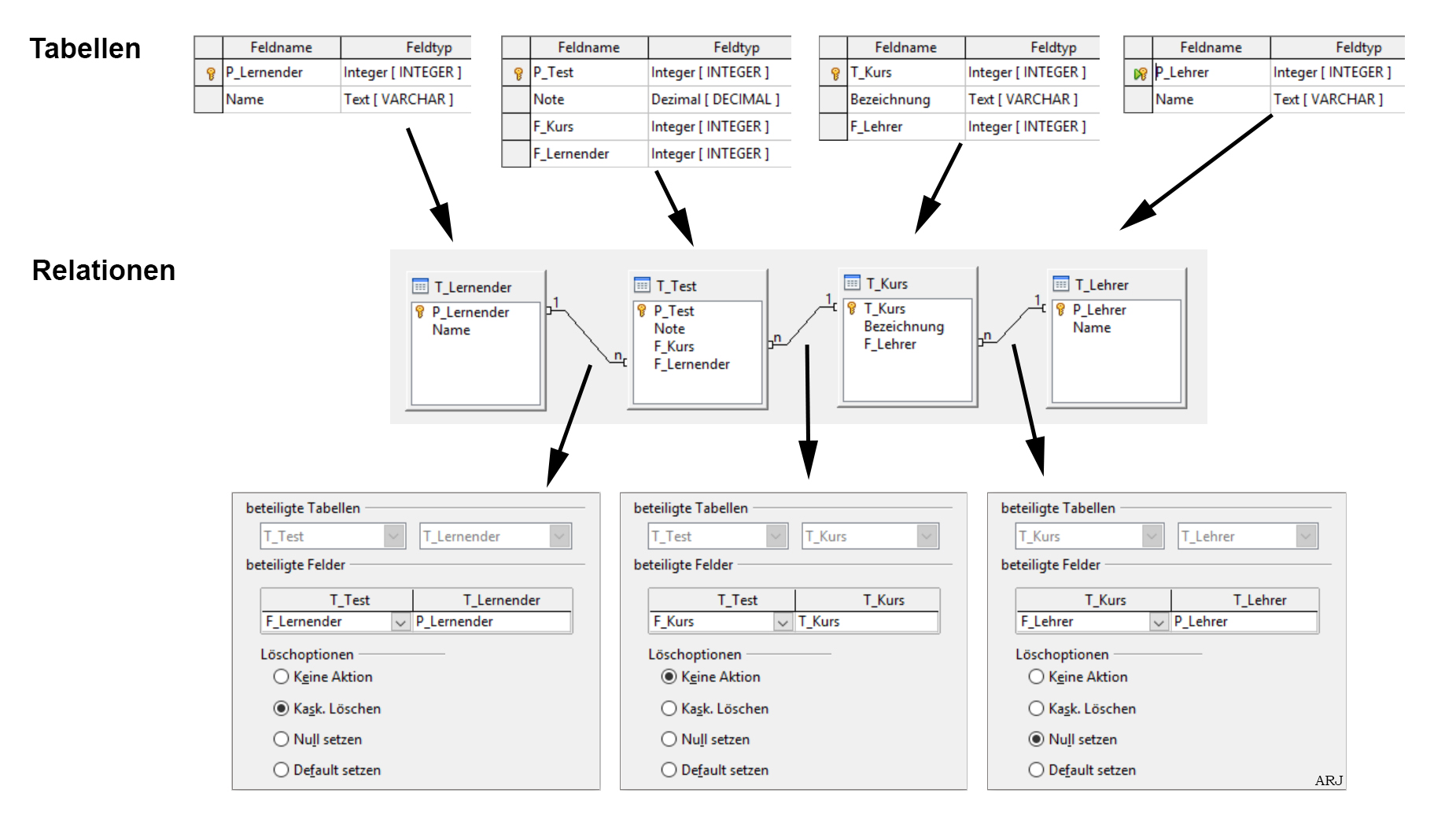
- T_Test zu T_Lernender: Jeder Test referenziert einen Lernenden. Falls der Lernende die Schule vorzeitig verlässt und somit sein Eintrag in der Tabelle T_Lernender gelöscht wird, ist auch ein allfällig bereits geleisteter Test obsolet. Die Löschoption bei der Beziehung zwischen den Tabellen T_Lernender und T_Test «Kask. Löschen» (= kaskadiert Löschen) führt dazu, dass ein Test gelöscht wird, falls der referenzierte Lernende gelöscht wird. (Integritätsbedingung: Ohne Lernenden gibt es auch keinen Test)
- T_Test zu T_Kurs: Jeder Test bezieht sich auf einen Kurs. Solange noch ein Test für einen Kurs existiert, darf dieser Kurs nicht aus der Datenbank gelöscht werden. Die Löschoption bei der Beziehung zwischen den Tabellen T_Kurs und T_Test «Keine Aktion» verhindert, dass ein referenzierter Datensatz aus der Tabelle T_Kurs gelöscht wird. (Integritätsbedingung: Zu jedem Test gibt es auch einen Kurs)
- T_Kurs zu T_Lehrer: Eine Kurs referenziert einen Lehrer. Falls der Lehrer die Schule verlässt und somit sein Eintrag in der Tabelle T_Lehrer gelöscht wird, bleibt der Kurs trotzdem bestehen, bzw. die Löschoption bei der Beziehung zwischen den Tabellen T_Lehrer und T_Kurs «Null setzen» bewirkt, dass in der Tabelle T_Kurs die Referenz auf den Lehrer auf NULL gesetzt wird. (Integritätsbedingung: der referenzierte Lehrer führt den Kurs)
∇ AUFGABEN
∇ LÖSUNGEN
3. DB-Entwurf Teil-B
Der folgende Teil beschreibt die DB-Modellierung
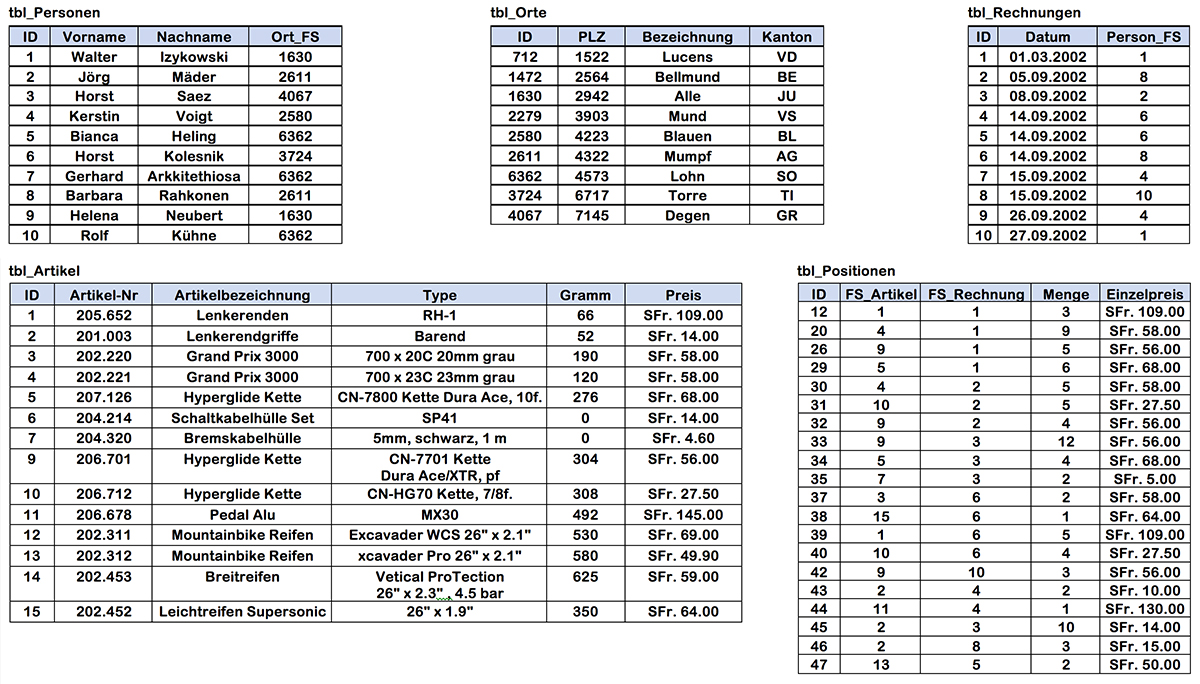
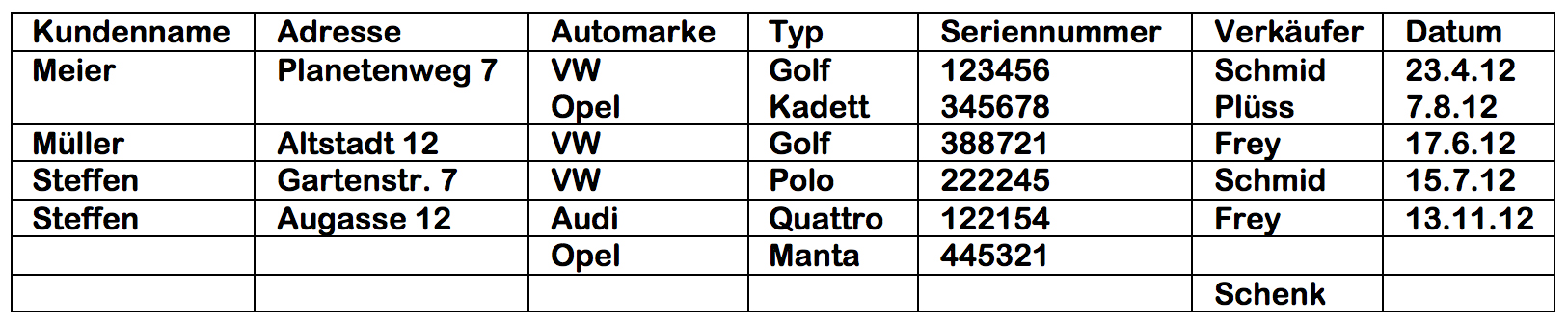
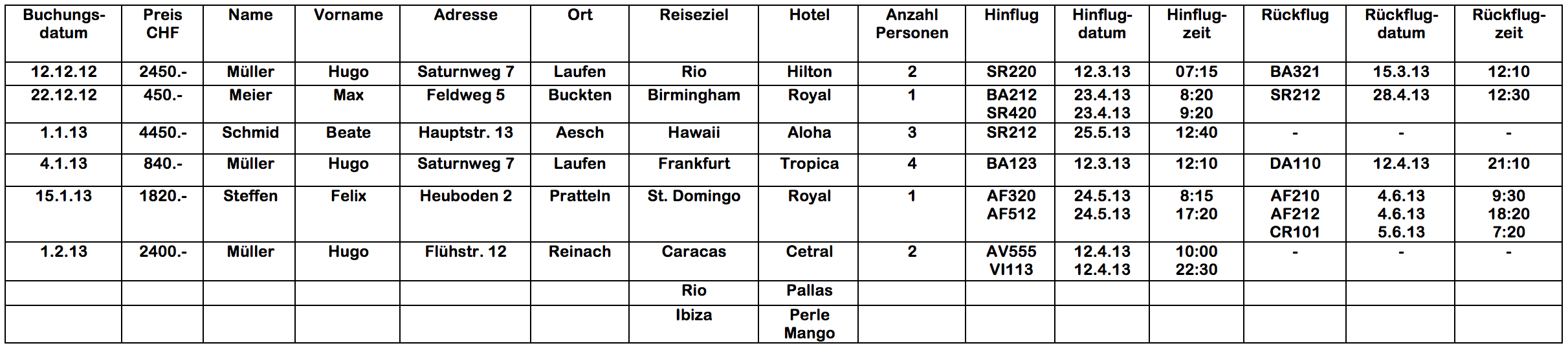
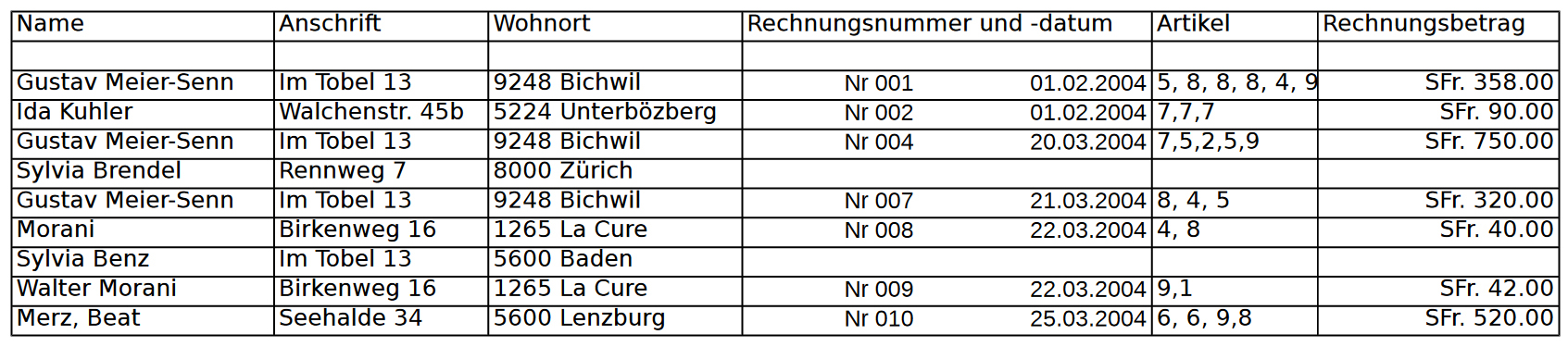
Das Negativbeispiel eines Datenbestands in Form einer Tabelle → Sehr häufig haben Systeme, die aus einer Anforderung heraus gewachsen sind und nicht konzeptionell entwickelt wurden, eine vergleichbare Struktur wie diese Tabelle "Versandhandel":Was kann schief gehen, wenn…
- … sie die Adresse von Gustav Meier-Senn auf «Im Tobel 18» korrigieren?
- … Walter Morani aus La Cure per heutigem Datum eine neue Rechnung bekommt, weil er die Artikel 4, 6, 2 und 9 gekauft hat?
- … Ida Kuhler alle Artikel der Rechnung Nr. 002 zurückgegeben hat?
- … Walter Morani den Artikel Nummer 9 von der Rechnung Nummer 009 zurückgibt?
3.1 Normalisierung von Relationen
Die Normalisierung ist die Zerlegung von Tabellen nach bestimmten Vorschriften. Ziele des Normalisierungsprozesses sind :- Die gesamte Information in der Datenbank ist redundanzfrei, dh. jedes Faktum, jeder Wert eines Attributes ist genau an einem Ort festgehalten
- Durch Modifikations- oder Einfügeoperationen können keine Widersprüche in den Daten auftreten (Speicheranomalien)
- Die Abfrage und Bearbeitung von Daten soll einfach und sicher sein. Normalisierte Tabellen bilden die Grundlage zu einer syntaktisch einfachen Datenmanipulationssprache
Speicheranomalien
Die Normalisierung hat unter anderem den Zweck, Widersprüche (Anomalien) zu verhindern. Ein Widerspruch ist sofort anhand der Daten in der Datenbank erkennbar, ohne dass man die zugrundeliegende Realität kennen muss. Falschinformation ist nur erkennbar, wenn man die Realität kennt. Das Erzeugen von Falschinformationen kann ein Datenbank-Management-System nicht verhindern, das Auftreten von Widersprüchen aber ohne weiteres. Wichtig ist die Tatsache, dass eine redundanzfreie Datenbank niemals Widersprüche enthalten kann. Die Idee bei relationalen Datenbanken ist daher, dass man eine Darstellungsform findet, in die niemals Redundanz eingebaut werden kann.
3.2 Normalisierungsprozess → Normalform 1 bis 3
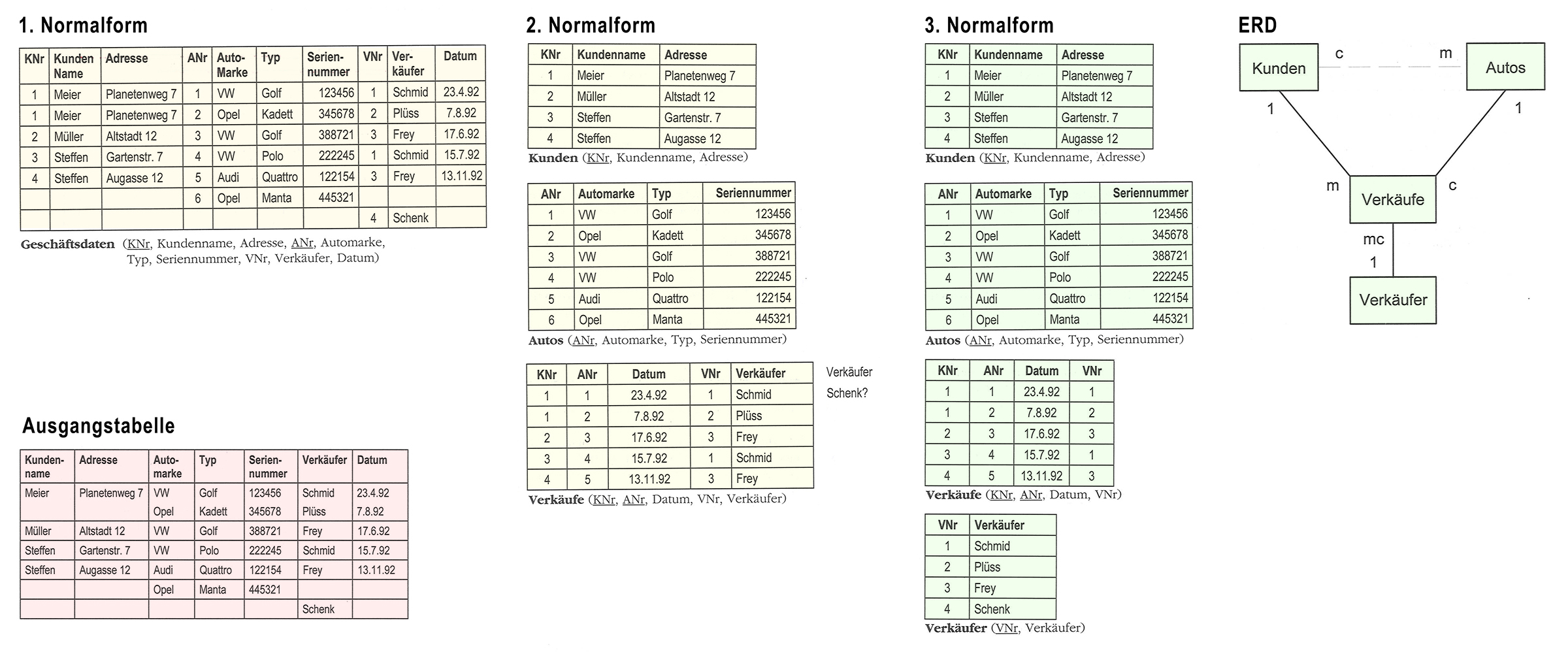
Der Normalisierungsprozess sei hier erklärt anhand des folgenden Beispiels:
Ausgangspunkt ist eine nicht-normalisierte Tabelle, in der Mitarbeiter in einer Garage, deren Abteilung und Aufträge erfasst sind: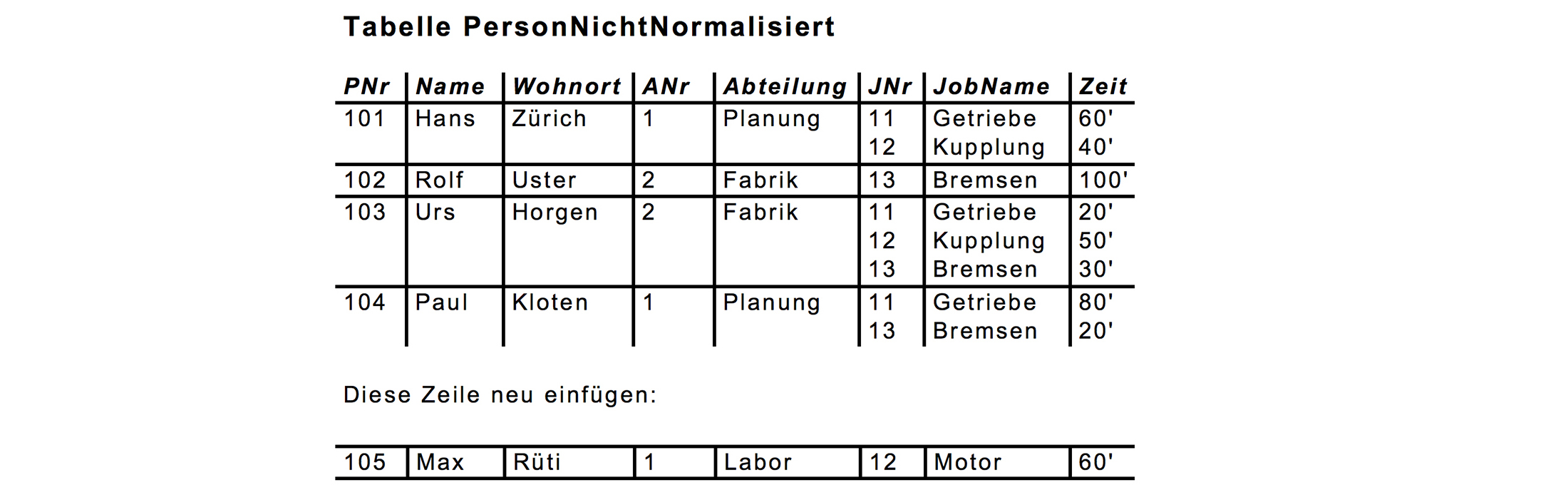 Würde man die Zeile mit «Max Rüti» neu in die Tabelle einfügen, wird dies zu einem Widerspruch führen.
Ein DBMS könnte diesen Widerspruch sofort erkennen, wenn die Tabelle der 3. Normalform genügen würde.
Würde man die Zeile mit «Max Rüti» neu in die Tabelle einfügen, wird dies zu einem Widerspruch führen.
Ein DBMS könnte diesen Widerspruch sofort erkennen, wenn die Tabelle der 3. Normalform genügen würde.
Im allgemeinen erreicht man beim Erstellen von Datenmodellen praktisch von selbst Tabellen, die sich in der ersten, zweiten oder sogar dritten Normalform befinden. Trotzdem müssen wir aber alle drei Normalformen kennenlernen und beginnen mit der obigen nicht-normalisierten Tabelle.Die Regeln zu dieser Garagen-Datenbank sind:
- Ein Mitarbeiter hat einen Namen
- Ein Mitarbeiter hat einen Wohnort
- Ein Mitarbeiter arbeitet in einer Abteilung
- Ein Mitarbeiter ist an mehreren Jobs beteiligt
- Jeder Job erfordert pro Mitarbeiter eine bestimmte Zeit
- Eine Abteilung hat einen Namen Jeder Job hat eine Nummer und einen Namen
- In einer Abteilung sind mehrere Mitarbeiter angestellt
- An einem Job sind mehrere Mitarbeiter beteiligt
Die erste Normalform
In der ersten Normalform sind keine mehrfachen Werte eines Attributes mehr zugelassen. Durch Angabe des Primärschlüssels ist der Wert von jedem Attribut eindeutig bestimmt.
Lehrsatz: Um eine Relation in die erste Normalform zu bringen, müssen alle existierenden Zeilen sooft kopiert und die mehrfach belegten Attribute auf die Kopien aufgeteilt werden, dass in jedem Feld nur noch ein Wert steht.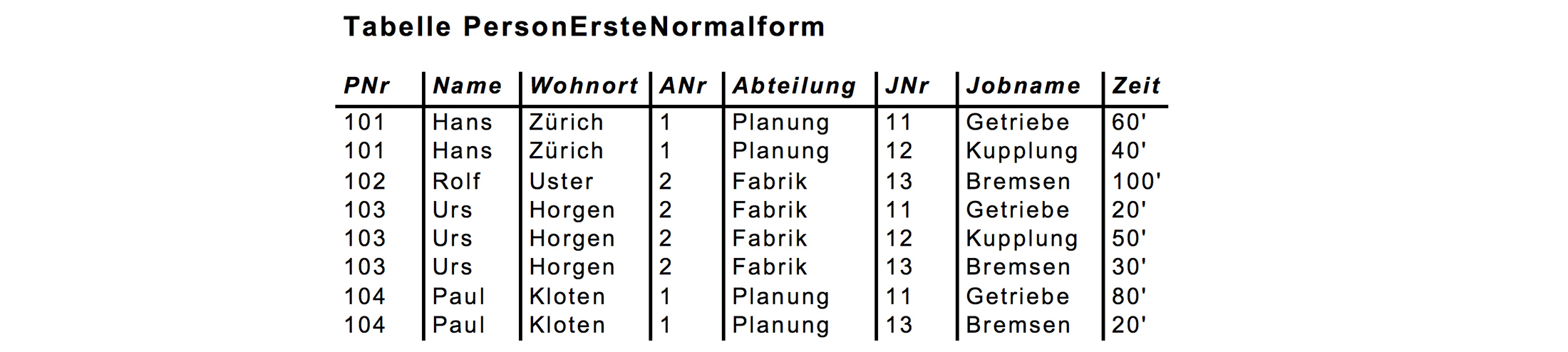 (Hinweis: Bei PNr handelt es sich um eine einfache Personalnummer. Diese stellt aber noch keinen Primärschlüssel dar!)
(Hinweis: Bei PNr handelt es sich um eine einfache Personalnummer. Diese stellt aber noch keinen Primärschlüssel dar!)
Was bewirkt die erste Normalform: Übersichtlichkeit.
Was ist noch nicht erfüllt: Sehr hohe Redundanz, Ändern und Einfügen schwierig, Speicheranomalien sind immer noch möglich.Die zweite Normalform
In obiger unnormalisierten Tabelle fällt auf, dass sie Attribute enthält, die gar nicht in einem inhaltlichen Zusammenhang miteinander stehen. Was hat zB. der Jobname mit dem Wohnort zu tun? In der zweiten Normalform wird die ursprüngliche Tabelle in kleinere Tabellen zerlegt, die nur noch Attribute enthalten, die effektiv miteinander in Beziehung stehen.
Lehrsatz: Eine Relation genügt der zweiten Normalform, wenn sie sich in der ersten Normalform befindet und jeder Attributwert eine Funktion des ganzen Schlüssel, und nicht nur eines Teils davon ist.
Schrittfolge zur Herstellung der 2. Normalform:- Primärschlüssel der gegebenen Relation festlegen, falls dieser nur aus einem Attribut besteht, liegt bereits 2.NF vor (Hinweis: Eine einfache Zeilennummerierung ist in diesem Sinne kein geeigneter Primärschlüssel!)
- Untersuchung, ob aus Teilschlüsselattributen bereits weitere Attribute folgen. Falls nicht, liegt bereits die 2. NF vor - Falls Abhängigkeiten gefunden werden, dann...
- Neue Relation bilden, die das Teilschlüsselattribut und alle von diesem abhängigen Nichtschlüsselattribute enthalten - Das Teilschlüsselattribut wird in der neuen Relation der Primärschlüssel
- Löschen der ausgelagerten Nichtschlüsselattribute in der Ausgangsrelation
- Vorgang ab 2. wiederholen, bis alle Nichtschlüsselattribute vom gesamten Schlüssel funktional abhängig sind.
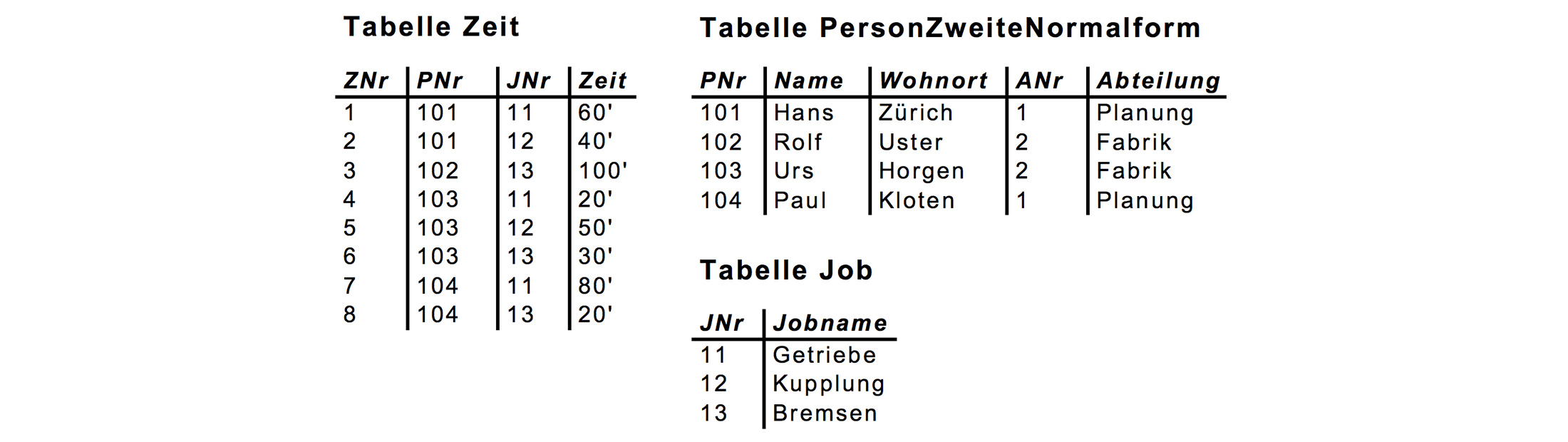 Was bewirkt die zweite Normalform: Reduktion von Redundanz.
Was bewirkt die zweite Normalform: Reduktion von Redundanz.
Was ist noch nicht erfüllt: Durch die Aufspaltung müssen bei einer Abfrage die Daten wieder zusammengesetzt werden. Ausserdem sind Speicheranomalien immer noch möglich aber nur noch in der Tabelle PersonZweiteNormalform.Die dritte Normalform
Aus der noch möglichen Speicheranomalie in der zweiten Normalform ergibt sich der Wunsch nach einer dritten Normalform.
Lehrsatz: Eine Relation befindet sich in der dritten Normalform, wenn sie den Forderungen der ersten und zweiten Normalform genügt und wenn alle Attribute, die nicht dem Schlüssel angehören, untereinander keine funktionale Abhängigkeit aufweisen.
Ist ein Attribut von einem anderen nicht dem Schlüssel angehörenden funktional abhängig, so muss dieses aus der Relation entfernt und zusammen mit dem Attribut von dem es abhängig ist in eine neu erstellte Relation eingefügt werden.
Schrittfolge zur Herstellung der 3. Normalform:- Untersuchung, ob aus Nichtschlüsselattributen andere Nichtschlüsselattribute folgen. Falls nicht liegt bereits die 3. NF vor - Falls Abhängigkeiten gefunden werden, dann...
- Neue Relation bilden, die das Nichtschlüsselattribut (wird nun Primärschlüssel der neuen Relation) und die von ihm abhängigen Attribute enthält
- Löschen der ausgelagerten Nichtschlüsselattribute mit Ausnahme des Attributes, das in der neuen Relation Primärschlüssel ist
- Vorgang ab 2. wiederholen, bis keine Abhängigkeiten mehr bestehen
 Was bewirkt die dritte Normalform: Sehr hohe Redundanzfreiheit. Widersprüche in der Datenbank sind ausgeschlossen.
Durch Einfügungen sind keine Speicheranomalien mehr möglich.
Was bewirkt die dritte Normalform: Sehr hohe Redundanzfreiheit. Widersprüche in der Datenbank sind ausgeschlossen.
Durch Einfügungen sind keine Speicheranomalien mehr möglich.
Die Tabellen unseres Beispiels als Resultat der Normalisierung bis zur dritten Normalform: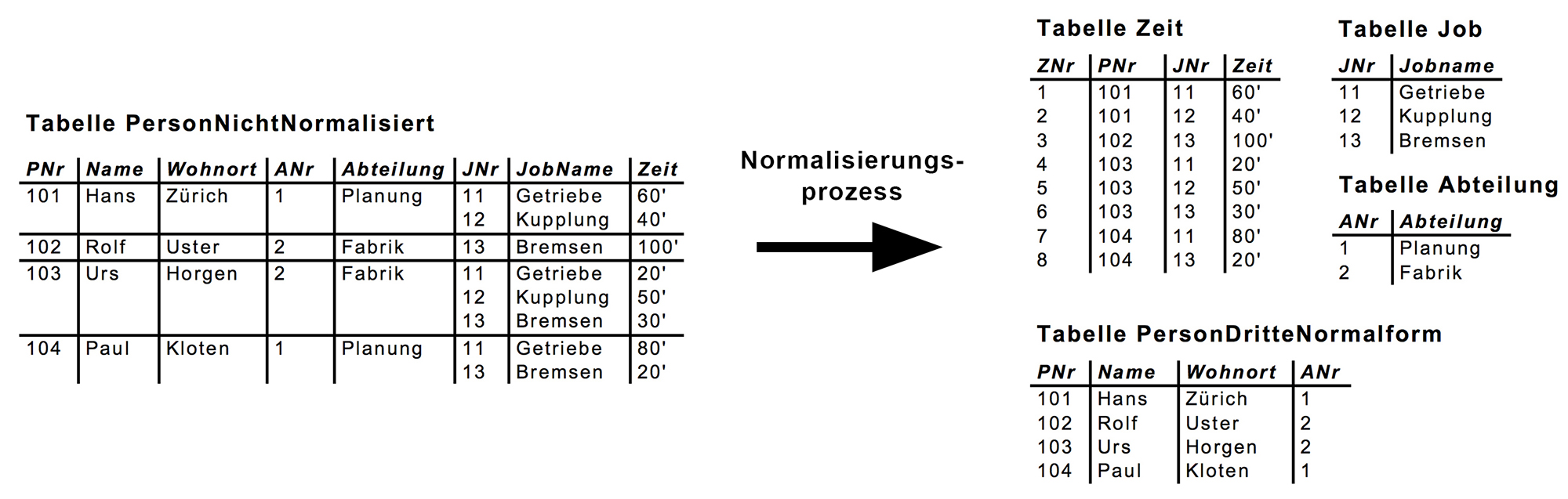
3.3 Rekursive Beziehungen
Beispiel für eine rekursive Beziehung «Klassisches Orchester»
Es gilt die Rahmenbedingung, dass ein Musiker auch gleichzeitig Dirigent sein kann und jeder Dirigent auch Musiker ist. Somit lassen sich folgende Beziehungen formulieren. Die 1-c Beziehung bedeutet, dass ein Musiker Dirigent sein kann und jeder Dirigent gleichzeitig auch Musiker ist. Die 1-m Beziehung bedeutet, dass jeder Musiker von genau einem Dirigenten dirigiert wird und dass jeder Dirigent mindestens einen Musiker dirigiert. Die beiden Beziehungen werden angeschrieben, damit der Sinn eindeutig erkennbar ist. Die entsprechende Tabelle müsste dann folgenden Aufbau haben: Diese Tabelle besitzt den Id-Schlüssel «MNr» (Musiker-Nr.) und den Fremdschlüssel «DNr» (Dirigenten-Nr.),
welcher aus den1 Id-Schlüssel «MNr» gebildet wurde. Auf den ersten Blick scheint dies zu funktionieren.
Es lässt sich klar bestimmen, dass Karajan ein Dirigent ist, welcher die Musiker Schmid, Bernstein und Müller dirigiert,
weil seine Musiker-Nr. im Attribut «DNr» vorkommt. Allerdings treten nun folgende Unstimmigkeiten auf:
Diese Tabelle besitzt den Id-Schlüssel «MNr» (Musiker-Nr.) und den Fremdschlüssel «DNr» (Dirigenten-Nr.),
welcher aus den1 Id-Schlüssel «MNr» gebildet wurde. Auf den ersten Blick scheint dies zu funktionieren.
Es lässt sich klar bestimmen, dass Karajan ein Dirigent ist, welcher die Musiker Schmid, Bernstein und Müller dirigiert,
weil seine Musiker-Nr. im Attribut «DNr» vorkommt. Allerdings treten nun folgende Unstimmigkeiten auf:
- Der Fremdschlüssel «DNr» müsste «MNr» heissen, weil «DNr» ja aus dem Id-Schlüssel «MNr» gebildet wurde. Dann hätten aber zwei Attribute die gleiche Bezeichnung.
- Wenn man wissen möchte, ob Karajan ein Dirigent ist, muss man alle Attributwerte von «DNr» nach den1 Id-Schlüsselwert von Karajan durchsuchen. Dies ist bei einer grossen Entitätsmenge unübersichtlich.
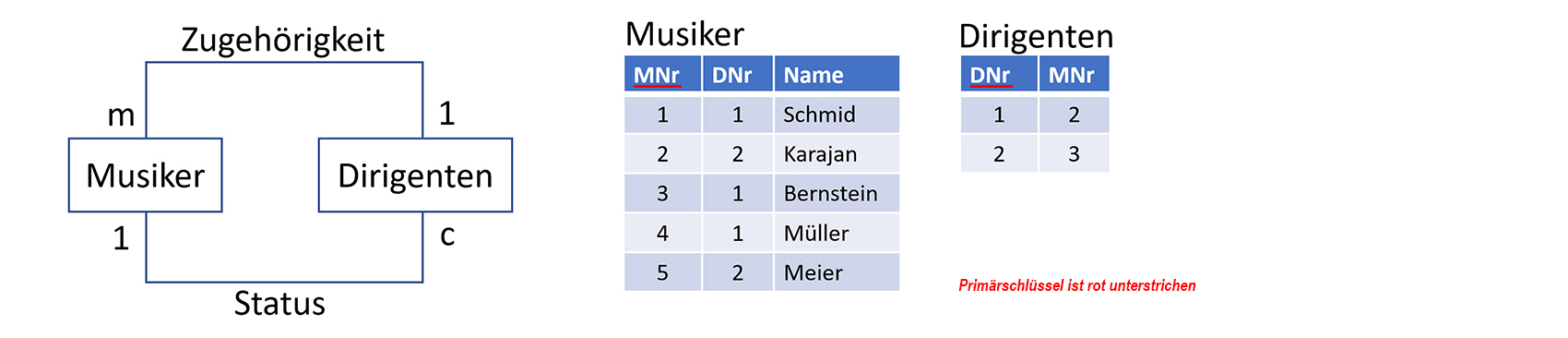 In der Tabelle «Musiker» sind nun diejenigen Daten aufgeführt, welche alle Musiker (und damit auch die Dirigenten) betreffen,
während man in der Tabelle «Dirigenten» spezifische Attribute einführen könnte, welche bestimmte Eigenschaften der Dirigenten beschreiben würden
(z.B. die Anzahl Dirigentenjahre).
In der Tabelle «Musiker» sind nun diejenigen Daten aufgeführt, welche alle Musiker (und damit auch die Dirigenten) betreffen,
während man in der Tabelle «Dirigenten» spezifische Attribute einführen könnte, welche bestimmte Eigenschaften der Dirigenten beschreiben würden
(z.B. die Anzahl Dirigentenjahre).
Man sieht nun aber, dass der Id-Schlüssel «MNr» vom Fremdschlüssel «DNr» abhängt und andererseits der Id-Schlüssel «DNr» vom Fremdschlüssel «MNr» abhängig ist. Dieser Sachverhalt macht sich bemerkbar, sobald man versucht, einen Musiker einzugeben. Dies gelingt nämlich nur, wenn die Dirigentennummer bekannt ist, weil Nullwerte in Fremdschlüsseln ja nicht erlaubt sind. Die Dirigentennummer hingegen bekommt man erst, wenn die Musikernummer bekannt ist. Die Beziehungen «Zugehörigkeit» und «Status» zwischen den beiden Tabellen «Musiker» und «Dirigenten» sind indirekt rekursiver Art und erzwingen die vorübergehende Verwendung von Nullwerten. Ergo ist auch diese Beziehung verboten, was zu einer erneuten Transformation führt.
Es musste eine neue Tabelle «Orchester» eingeführt werden, welche mit der Tabelle «Dirigenten» in einer 1-1 Beziehung steht. Die drei Tabellen haben nun folgenden Aufbau: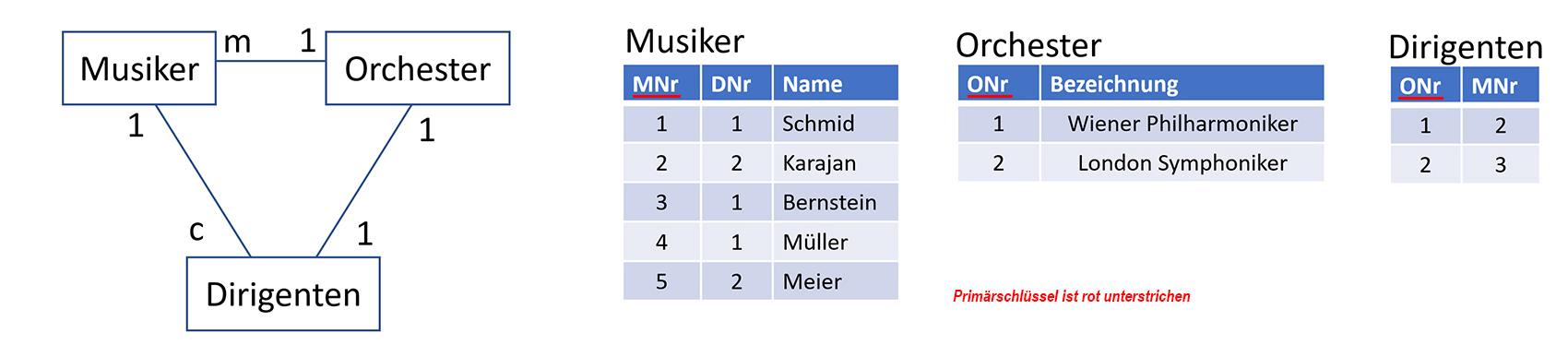 Mit dieser Transformation wurden alle rekursiven Beziehungen beseitigt und der Id-Schlüssel «DNr» eliminiert. Bei der Dateneingabe müssen nun zuerst die Orchester definiert werden.
Danach können die Musiker und zuletzt ‚die Dirigenten eingegeben werden. Es ist eindeutig definiert, dass der Musiker «Schmid»
bei den Wiener Philharmonikern spielt und damit von Karajan dirigiert wird. Dieses Beispiel zeigt, dass auch eine 1-1 Beziehung ihre Berechtigung hat,
denn eine Zusammenlegung der beiden Tabellen «Orchester» und «Dirigenten» ist nicht möglich, weil sonst Nullwerte beim Fremdschlüssel MNr entstehen könnten.
Mit dieser Transformation wurden alle rekursiven Beziehungen beseitigt und der Id-Schlüssel «DNr» eliminiert. Bei der Dateneingabe müssen nun zuerst die Orchester definiert werden.
Danach können die Musiker und zuletzt ‚die Dirigenten eingegeben werden. Es ist eindeutig definiert, dass der Musiker «Schmid»
bei den Wiener Philharmonikern spielt und damit von Karajan dirigiert wird. Dieses Beispiel zeigt, dass auch eine 1-1 Beziehung ihre Berechtigung hat,
denn eine Zusammenlegung der beiden Tabellen «Orchester» und «Dirigenten» ist nicht möglich, weil sonst Nullwerte beim Fremdschlüssel MNr entstehen könnten.
3.4 Generalisierung/Spezialisierung
Es gibt den Spezialfall, dass die Entitätsmengen von zwei- oder mehreren Tabellen Teilmengen einer übergeordneten Entitätsmenge sind. Beispielsweise könnte eine übergeordnete Entitätsmenge «Firmenpersonal» in die Untermengen «Angestellte» und «Aushilfen» aufgeteilt werden. In der Tabelle «Angestellte» können dann zusätzliche Attribute verwendet werden, welche die speziellen Eigenschaften eines Angestellten beschreiben und in der Tabelle «Firmenpersonal» nicht vorhanden sind, weil sie nicht generell für alle Personen gelten. Die Tabelle «Firmenpersonal» bezeichnet man als generalisierte Tabelle, während die Tabellen «Aushilfen» und ««Angestellte» als spezialisierte Tabellen bezeichnet werden. Die generalisierte Entitätsmenge umfasst dabei die spezialisierten Entitätsmengen vollständig. Es existieren also keine Tupel in den spezialisierten Tabellen, welche in der generalisierten Tabelle nicht vorkommen. Diese Unter- und Obermengenbeziehungen lassen sich in drei verschiedene Fälle einteilen:
- Spezialisierte Entitätsmengen mit zugelassener Überlappung
- Generalisierte Entitätsmenge mit vollständiger Überdeckung
- Spezialisierte Entitätsmengen ohne Überlappung
A: Zugelassene Überlappung:
Wenn man die Entitätsmengen dieser Beziehungsart grafisch darstellt, ergibts sich folgendes Bild:
 Die Entitätsmenge der Tabelle «Flugapparate» beinhaltet die Entitätsmengen der Tabellen «Segelflugzeuge» und «Motorflugzeuge».
In der Tabelle «Flugapparate» können nun Tupel existieren, deren Id-Schlüsselwert als Fremdschlüssel...
Die Entitätsmenge der Tabelle «Flugapparate» beinhaltet die Entitätsmengen der Tabellen «Segelflugzeuge» und «Motorflugzeuge».
In der Tabelle «Flugapparate» können nun Tupel existieren, deren Id-Schlüsselwert als Fremdschlüssel...
- nicht in den Tabellen «Segelflugzeuge» und «Motorflugzeuge» vorkommt
- in beiden Tabellen «Segelflugzeuge» und «Motorflugzeuge» vorkommt
- nur in einer der beiden Tabellen «Segelflugzeuge» und «Motorflugzeuge» vorkommt
 Die Tabelle «Flugapparate» umfasst alle flugtauglichen Objekte des Flugsportvereins.
Die zweite Tabelle «Segelflugzeuge» beinhaltet alle nichtmotorisierten Tragflächenflugzeuge und die dritte Tabelle «Motorflugzeuge» beinhaltet alle motorisierten Flugzeuge.
Die Tabelle «Flugapparate» umfasst alle flugtauglichen Objekte des Flugsportvereins.
Die zweite Tabelle «Segelflugzeuge» beinhaltet alle nichtmotorisierten Tragflächenflugzeuge und die dritte Tabelle «Motorflugzeuge» beinhaltet alle motorisierten Flugzeuge.
In der Entitätsmenge «Flugapparate» kommen auch Flugapparate wie der Heissluftballon vor, welche nicht den Untermengen «Segelflugzeuge» und «Motorflugzeuge» angehören. Der Flugapparat Nr. 6 ist ein Segelflugzeug mit Hilfsmotor und gehört sowohl der Entitätsmenge «Segelflugzeuge» als auch der Entitätsmenge «Motorflugzeuge» an. Als Id-Schlüssel der Tabellen «Segelflugzeuge» und «Motorflugzeuge» findet der Id-Schlüssel «FNr» der Tabelle «Flugapparate» verwendung.B: Vollständige Überdeckung
Wenn man die Entitätsmengen dieser Beziehungsart grafisch darstellt, ergibt sich folgendes Bild:
 Die Entitätsmenge der Tabelle «Flugapparate» («Flugapparate» besteht hier vollständig aus den Entitätsmengen der
Tabellen «Segelflugzeuge» und «Motorflugzeuge»). In der Tabelle «Flugapparate» existieren keine Tupel, deren
Id-Schlüsselwert nicht in den Tabellen «Segelflugzeuge» und «Motorflugzeuge» als Fremdschlüssel vorkommt.
Die Entitätsmenge der Tabelle «Flugapparate» («Flugapparate» besteht hier vollständig aus den Entitätsmengen der
Tabellen «Segelflugzeuge» und «Motorflugzeuge»). In der Tabelle «Flugapparate» existieren keine Tupel, deren
Id-Schlüsselwert nicht in den Tabellen «Segelflugzeuge» und «Motorflugzeuge» als Fremdschlüssel vorkommt.
Das Entitätenblockdiagramm und die Tabellen sehen folgendermassen aus: Die Tabelle «Flugapparate» umfasst wiederum alle Flugzeuge des Flugsportvereins. Die Tabelle «Segelflugzeuge» beinhaltet alle Segelflugzeuge
und die Tabelle «Motorflugzeuge» beinhaltet alle Motorflugzeuge. Diesmal existieren in der Tabelle «Flugapparate» nur Tupel,
deren Id-Schlüssel als Fremdschlüssel entweder in der Tabelle «Segelflugzeuge» oder in der Tabelle «Motorflugzeuge» vorkommt.
Die Tabelle «Flugapparate» umfasst wiederum alle Flugzeuge des Flugsportvereins. Die Tabelle «Segelflugzeuge» beinhaltet alle Segelflugzeuge
und die Tabelle «Motorflugzeuge» beinhaltet alle Motorflugzeuge. Diesmal existieren in der Tabelle «Flugapparate» nur Tupel,
deren Id-Schlüssel als Fremdschlüssel entweder in der Tabelle «Segelflugzeuge» oder in der Tabelle «Motorflugzeuge» vorkommt.
Das Attribut «Klasse» gibt an, in welcher spezialisierten Tabelle ein Tupel zu finden ist (S = Segelflugzeuge, M = Motorflugzeuge). Es wird als diskriminierendes Attribut bezeichnet. Im Gegensatz zur zugelassenen Überlappung, kann hier für jedes Tupel klar angegeben werden, zu welcher spezialisierten Tabelle es gehört.C: Überlappung nicht zugelassen:
Wenn man die Entitätsmengen dieser Beziehungsart grafisch darstellt, ergibt sich folgendes Bild:
 Dieser Fall präsentiert sich ähnlich, wie die zugelassene überlappung. Der einzige Unterschied besteht darin, dass sich die spezialisierten Entitätsmengen nicht überlappen.
Auch hier kann klar angegeben werden, zu welcher spezialisierten Tabelle ein Tupel gehört. Somit muss, wie beim Fall der vollständigen überdeckung, ein diskriminierendes Attribut verwendet werden.
Dieser Fall präsentiert sich ähnlich, wie die zugelassene überlappung. Der einzige Unterschied besteht darin, dass sich die spezialisierten Entitätsmengen nicht überlappen.
Auch hier kann klar angegeben werden, zu welcher spezialisierten Tabelle ein Tupel gehört. Somit muss, wie beim Fall der vollständigen überdeckung, ein diskriminierendes Attribut verwendet werden.
Das Entitätenblockdiagramm und die Tabellen sehen folgendermassen aus: Die Tabelle «Flugapparate» umfasst wiederum alle Flugzeuge des Flugsportvereins. Die Tabelle «Segelflugzeuge» beinhaltet alle Segelflugzeuge und die Tabelle «Motorflugzeuge» beinhaltet alle Motorflugzeuge.
Diesmal existieren in der Tabelle «Flugapparate» keine Tupel, deren Id-Schlüsselwert sowohl in der Tabelle «Segelflugzeuge» als auch in der Tabelle «Motorflugzeuge» vorkommt.
Die Tabelle «Flugapparate» umfasst wiederum alle Flugzeuge des Flugsportvereins. Die Tabelle «Segelflugzeuge» beinhaltet alle Segelflugzeuge und die Tabelle «Motorflugzeuge» beinhaltet alle Motorflugzeuge.
Diesmal existieren in der Tabelle «Flugapparate» keine Tupel, deren Id-Schlüsselwert sowohl in der Tabelle «Segelflugzeuge» als auch in der Tabelle «Motorflugzeuge» vorkommt.
Der Attributwert «A» im diskriminierenden Attribut «Klasse» bedeutet «anderes Fluggerät». Das Fluggerät Nr. 3 kommt in den spezialisierten Tabellen nicht vor.
∇ AUFGABEN
∇ LÖSUNGEN
4. DB-Transaktionen
Folgende Operationen sollen effizient, widerspruchsfrei (Konsistenz) und makellos (Integrität) abgearbeitet werden:

4.1 Die Structured Query Language SQL
SQL ist eine Universalsprache für Datenbanken. Der Name SQL war ursprünglich die Abkürzung für «Structured Query Language», was jedoch nicht bedeutet, dass SQL nur eine Abfragesprache ist. Heute ist SQL eine Sprache zur strukturierten Abfrage, Aktualisierung, Datendefinition, Datenüberprüfung, Sicherung der Konsistenz und des gleichzeitigen Zugriffs, ferner zur Pflege des Datenkataloges und vieles mehr.
Die Sprache SQL wird in verschiedene Sprachbereiche eingeteilt:- Data Definition Language: Beinhaltet Kommandos zur Definition und Veränderung der Struktur von DB-Objekten und Kommandos zur Datensicherheit.
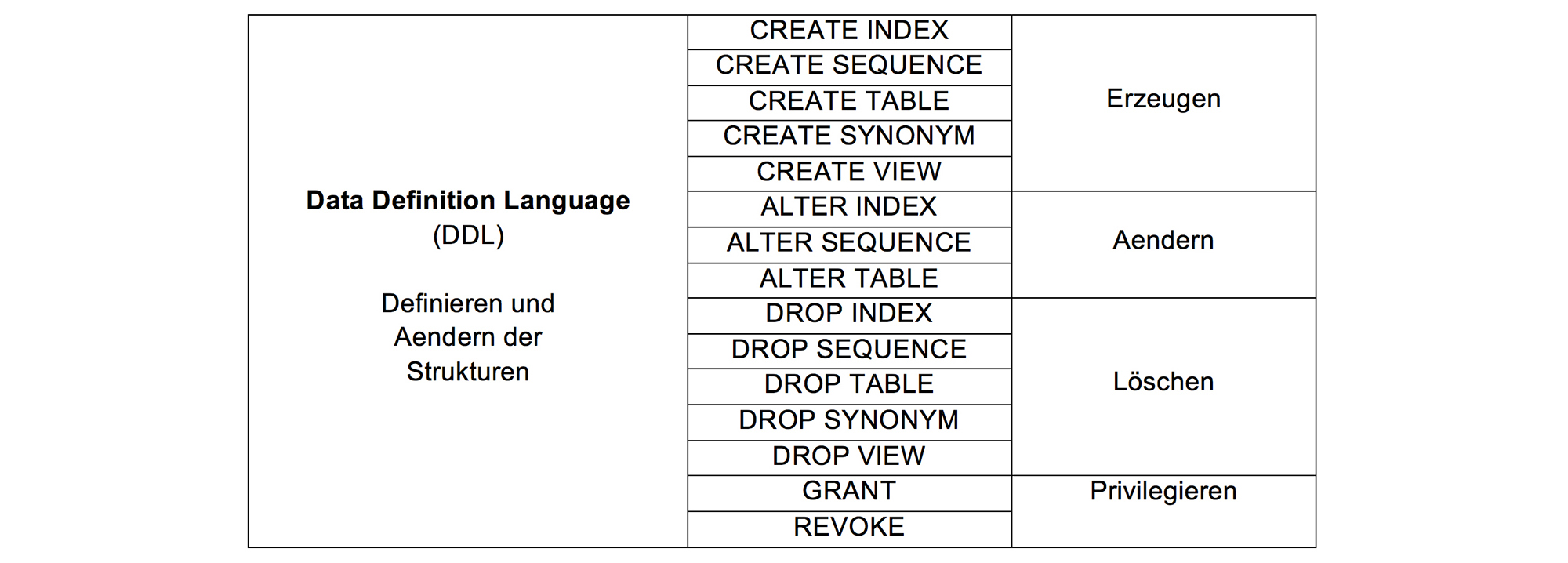
- Data Manipulation Language: Manipulieren und Fragen Daten aus existierenden Objekten ab.

- Transaction Control Kommando: Tragen zur Transaktionssteuerung bei.

- Session Control Kommando: Regeln dynamisch die Eigenschaften einer User-Session.

4.2 Mit SQL Tabellen erzeugen & bearbeiten
- Neue Tabelle erzeugen:
create table adressen ( p_id int NOT NULL UNIQUE, name char(50), vorname char(30), jahrgang integer, telefonnr char(15), strasse char(100), plz char(6), ort char(30), kfz_kontrollschild char(16) ); (NOT NULL & UNIQUE → Damit erzwingt man für den Primärschlüssel «p_id» einen einzigartigen Eintrag.) (LibreOfficeBase-Beispiel. Anschliessend unter «Ansicht» → «Tabellen aktualisieren» lassen!) create table "Tabelle1" ( "TB1Primary_ID" integer, "myAttribut_A" varchar(50), "myAttribut_B" integer, "TB2Foreign_ID" integer, Primary Key ("TB1Primary_ID") ); - Relationen zwischen Entitäten (Tabellen) definieren:
(LibreOfficeBase Beispiel für die folgende Situation: In Tabelle1 existiert ein Fremdschlüssel TB2Foreign_ID der in Tabelle2 Primärschlüssel mit dem Namen TB2Primary_ID ist.)alter table "Tabelle1" add constraint "constraintobject" foreign key ("TB2Foreign_ID") references "Tabelle2" ("TB2Primary_ID"); (Hinweis: Fehlt dieser Constraint, kann die DB z.B. referentielle Integrität nicht sicherstellen.) - Unique-Constraint ergänzen: Damit erreicht man, dass kein Wert in «kfz_kontrollschild» mehrmals vorkommt.
alter table adressen add unique kfz_kontrollschild; (LibreOfficeBase Beispiel:) alter table "Tabelle1" add unique ("myAttribut_A"); - Tabelleneintrag mit INSERT:
insert into adressen values ( 'Keller', 'Hans', 64, '031 111 22 33', 'Bahnhofstrasse 1', '3000', 'Bern' );
- Tabelleneintrag löschen mit DELETE:
delete from adressen where name = 'Keller' and vorname = 'Hans';
4.3 Mit SQL Tabellen abfragen
- Die SELECT-Klausel wählt bestimmte Spalten oder abgeleitete Spaltenwerte aus
- Nach FROM folgt die Angabe der Tabelle oder eine Liste von Tabellen, mit denen im SELECT-Befehl gearbeitet wird
- WHERE-Klausel : Die Werte in den Feldern müssen einer spezifischen Bedingung oder einer Anzahl von Bedingungen entsprechen
- ORDER BY spezifiziert die Sortierkriterien, nach denen das Abfrageergebnis ausgegeben werden soll.

- SELECT/FROM-Klausel:
Mit dem Select spezifiziert man die Ergebnisses der Abfrage. Der Stern bei select * soll heissen, dass alle Spalten einer Tabelle ausgegeben werden sollen. Ein Select-Ausdruck kann Konstanten, arithmetische Ausdrücke, und Funktionen enthalten. Zum SELECT gehört immer ein FROM, mit dem man die Tabelle (oder mehrere Tabellen) auswählt, aus welcher Spaltenwerte ausgelesen werden sollen. select * from personal; select Pers_Nr, Name from Personal; select sum(Gehalt*13), sum(Bonus*13) from Personal; select Name as "MITARBEITER", Gehalt*13 as "JAHRESSALAER" from Personal;
- WHERE-Klausel:
Enthält eine oder mehrere Suchbedingungen, denen die Zeilen genügen müssen, um angezeigt zu werden. Mehrere Bedingungen kann man mit arithmetische Vergleichsoperatoren und logischen Operatoren NOT, AND und OR verknüpfen. select * from Personal where Name = "Keller“ select Name, Gehalt from Personal where Gehalt between 4000 and 6000; select * from Personal where Name like "*ei*“; select Name, Bonus from Personal where Bonus is not null; select Name, Abt_Nr from Personal where Abt_Nr not in (10, 30); select sum(Gehalt*13), sum(Bonus*13) from Personal where Beruf = "Verkaeufer"; select 13*avg(Gehalt + Bonus) as "Durchschnitt Jahressalaer Verkauf" from Personal where Beruf = "Verkaeufer"; select max(Gehalt) as "MAX", min(Gehalt)
as "MIN", max(Gehalt) – min(Gehalt) as "DIFF" from Personal; - ORDER BY-Klausel:
Order by bestimmt die Kriterien der Zeilensortierung bei Abfrageergebnissen. select Name, Gehalt from Personal order by Gehalt;
4.4 Mit SQL Tabellen verknüpfen
Alle bisherigen SQL-Beispiele beziehen sich auf die eine Tabelle Personal. Oft sind Abfragen über mehrere Tabellen verlangt. Das Konstrukt dass dies ermöglicht, nennt man Join. Ein Join ist immer dann notwendig, wenn Daten in mehreren Tabellen gehalten werden, diese Tabellen (Personal, Abteilung) aber in einer Beziehung zueinander stehen und daher zusammen angezeigt werden müssen. Diese Beziehung wird meist über die Primärschlüssel und Fremsschlüsselspalte realisiert. In den Besipieltabellen Personal und Abteilung ist die Beziehung über die Spalte Abt_Nr modelliert, die in der Abteilung-Tabelle Primärschlüssel und in der Personal-Tabelle Fremdschlüssel ist. Die folgenden SQL-Beispiele beziehen sich wiederum auf diese beiden Tabellen:
- CROSS-Join: Kartesisches Produkt der Tabellen. Dabei wird jeder Datensatz der einen Tabelle
mit jedem anderen der anderen Tabelle gepaart. Das ergibt bei grossen Ausgangstabellen sehr grosse Resultatstabellen.
Bsp. Tabelle1 mit 100 Einträgen und Tabelle2 mit 100 Einträgen ergeben 100 * 100 = 10000 Kombinationen.
(Das Weglassen von cross join und Ersetzen durch ein Komma sollte übrigens zum selben Ziel führen.)select Name, Abt_Name from Personal cross join Abteilung;
- LEFT-Join: Alle Mitarbeiter, auch die ohne Abteilungsnamen.
select Name, Abt_Name from Personal left join Abteilung on Personal.Abt_Nr = Abteilung.Abt_Nr; Obwohl der folgende Join mit Where zum gleichen Resultat führt, ist diese Variante ineffizient, insbesondere bei grossen Datenbeständen, wo das zuerst gebildete kartesische Produkt viel Zwischenspeicher erfordert, bevor dann mit where die gültigen Kombinationen herausgefiltert werden: select Name, Abt_Name from Personal left join Abteilung where Personal.Abt_Nr = Abteilung.Abt_Nr; Resultat: Schmid/Forschung , Altherr/Verkauf , Waser/Verkauf , Jordi/Forschung , Meier/Verkauf , Bauer/Verkauf , Calvo/Verwaltung , Schneider/Forschung , Keller/Verwaltung , Tanner/_ , Ammann/_ , Jung/Verkauf , Frei/Forschung , Morf/Verwaltung LibreOfficeBase-Beispiel: select "Tabelle1"."Attribut2", "Tabelle2"."Attribut2" from { oj "Tabelle1" left outer join "Tabelle2" on "Tabelle1"."FK" = "Tabelle2"."PK" } - RIGHT-Join: Nur Mitarbeiter mit Abteilungsnamen, auch Abteilungsnamen ohne Mitarbeiter.
select Name, Abt_Name from Personal right join Abteilung on Personal.Abt_Nr = Abteilung.Abt_Nr; Resultat: Schmid/Forschung , Altherr/Verkauf , Waser/Verkauf , Jordi/Forschung , Meier/Verkauf , Bauer/Verkauf , Calvo/Verwaltung , Schneider/Forschung , Keller/Verwaltung , Jung/Verkauf , Frei/Forschung , Morf/Verwaltung , _/Datenbunker In LibreOfficeBase: select "Tabelle1"."Attribut2", "Tabelle2"."Attribut2" from { oj "Tabelle1" right outer join "Tabelle2" on "Tabelle1"."FK" = "Tabelle2"."PK" } - INNER-Join: Nur Mitarbeiter mit dazugehörigem Abteilungsnamen. (Keine "leeren" Mitarbeiter bzw. Abteilungen)
select Name, Abt_Name from Personal inner join Abteilung on Personal.Abt_Nr = Abteilung.Abt_Nr; Resultat: Schmid/Forschung , Altherr/Verkauf , Waser/Verkauf , Jordi/Forschung , Meier/Verkauf , Bauer/Verkauf , Calvo/Verwaltung , Schneider/Forschung , Keller/Verwaltung , Jung/Verkauf , Frei/Forschung , Morf/Verwaltung Explizite Variante gem. SQL-92-Standard mit kartesischer Produktbildung: select Name, Abt_Name from Personal, Abteilung where Personal.Abt_Nr = Abteilung.Abt_Nr;
- SELF-Join: Die Tabelle Personal wird zweimal angesprochen, also mit sich selber verknüpft.
(Das wird möglich durch die Verwendung der unterschiedlichen Alias-Namen angestellter und vorgesetzter.)select angestellter.Name, vorgesetzter.Name as "BOSS" from Personal angestellter, Personal vorgesetzter where angestellter.Vorgesetzter = vorgesetzter.Pers_Nr; select Name, Beruf from Personal p, Abteilung a where p.Abt_Nr = a.Abt_Nr and Arbeitsort = "Genf";
- Die JOIN-Alternative → Unterabfrage SUBQUERY: Anstatt die Aufgabe mit einem Equi-Join zu lösen,
wäre auch eine sogenannte Subquery denkbar. Dabei wird in die where-Klausel eine vollständige select-Anweisung eingebunden.
select Name, Beruf from Personal where Abt_Nr in (select Abt_Nr from Abteilung where Arbeitsort = "Genf");
∇ AUFGABEN
5. Abfragen und Formulare erstellen
Nachdem die Datenbasis (Tabellen und Beziehungen) erstellt wurde, soll sie nun mit Inhalt befüllt werden. Dazu benötigen wir ein entsprechendes Hilfsmittel, den sogenannten Maskengenerator, welcher die Entwicklung von benutzerdefinierten Eingabemasken unterstützen und eine Verbindung zwischen dem Benutzer und der Datenbank darstellt.
Die Benutzermaske hat folgende Aufgaben:- Ermöglicht das komfortable Editieren und Abfragen von Daten
- Trägt massgeblich zur Erhaltung der Datenkonsistenz bei, indem Benutzereingaben und Aktionen auf deren Richtigkeit hin überprüft werden
- Kann komplexe Transaktionen durchführen, welche die Arbeit der Benutzer wesentlich vereinfacht
- Formulare entsprechen den hier beschriebenen Benutzermasken und beziehen sich auf eine Tabelle
- Abfragen dienen als Basis für den Reportgenerator
- Berichte ist der eigentliche Reportgenerator der formatierte Listen erstellt
Formularaufteilung in:- Stammdaten: Beschreiben Geschäftsobjekte (z.B. der Kundenstamm, Artikelgruppe etc.), die nur in Ausnahmefällen verändert werden. Diese Daten werden meist schon vor dem Produktiveinsatz angelegt oder aus Altanwendungen übernommen. Änderungen und Erweiterungen an diesen Datenbeständen werden bei Bedarf vorgenommen, sind aber nicht sehr häufig. Stammdaten zeichnen sich somit durch eine gewisse Dauerhaftigkeit aus.
- Bestandsdaten: Weisen Bestände (z.B. Anzahl Exemplare des Produkts XY) aus und beschreiben somit einen Zustand. Sie kennzeichnen die betriebliche Mengen- und Wertestruktur und werden fortlaufend aktualisiert.
- Bewegungsdaten: Bewegungsdaten beschreiben Ereignisse (z.B. Bestellungen, Aufträge, Mahnungen etc.) und zeichnen sich durch ihren Zeitbezug aus, d.h. Bewegungsdaten werden bei jedem Geschäftsvorfall erfasst. Sie dienen der Abbildung der Wertflüsse und Bestandsveränderungen im System in Form von mengen- oder wertmäßigen Zu- und Abgängen.
5.1 Abfragen in LibreOffice-Base
Tabellen auswählen
Wählen Sie die Tabellen aus, aus denen Sie Daten beziehen möchten. Es können nachträglich weitere Tabellen hinzugefügt werden. Überprüfen Sie, ob die Beziehungen (Relationen) zwischen den Tabellen erstellt sind.
Hinweis: Wenn keine Relationen existieren, erstellt die DB eine vollständige Kombination der beteiligten Tabellen (Jeder Datensatz wird mit jedem Datensatz kombiniert), was kaum erwünscht ist.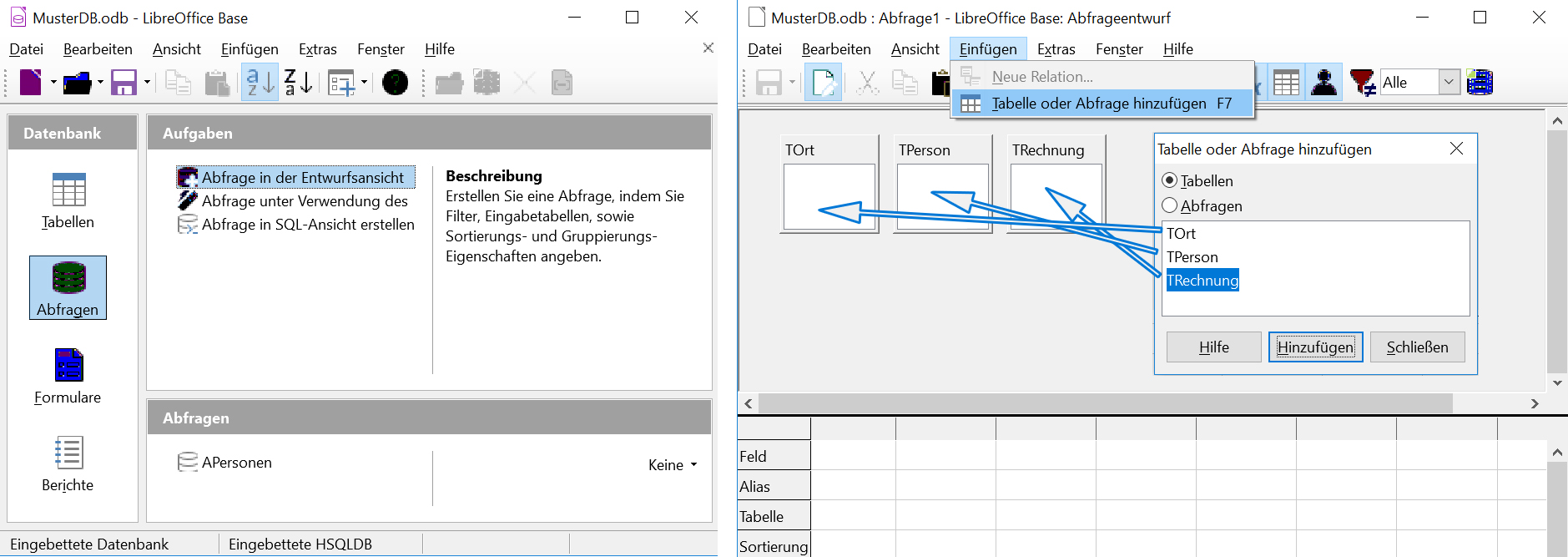
Attribute auswählen
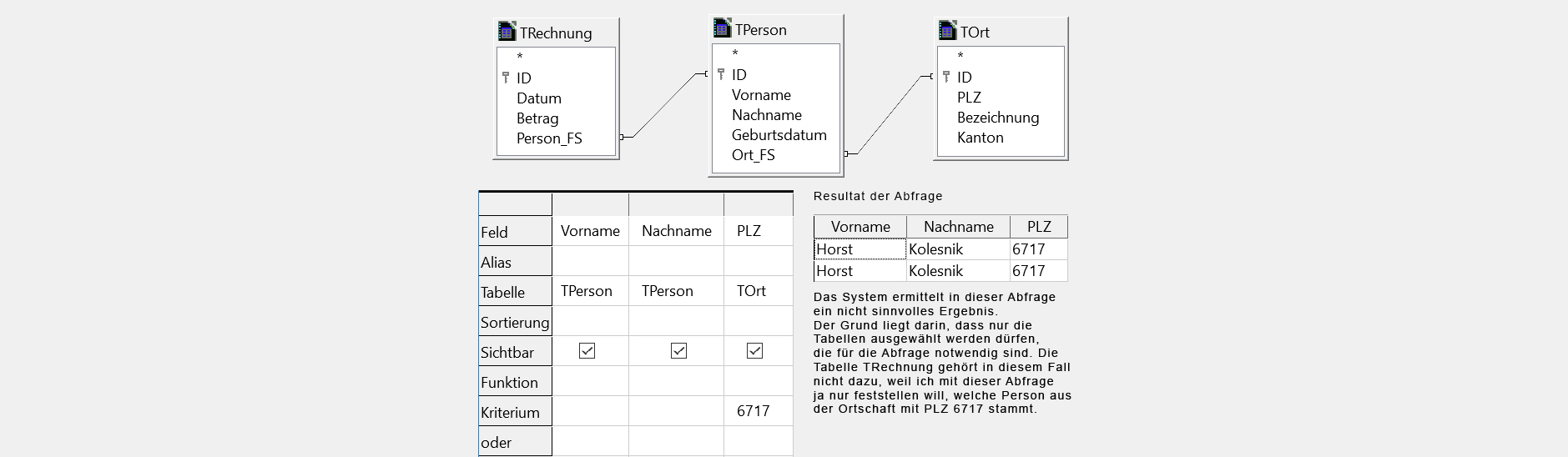
Klicken Sie in den Tabellen die Attribute an, die angezeigt werden sollen. Die Attribute werden automatisch in die unteren Felder eingetragen und können, wenn erforderlich, auch wieder von dort entfernt oder in der Anordnung verschoben werden. Mit der Funktionstaste F5 können Sie sich direkt das Resultat anzeigen lassen. Mit F4 lässt sich diese Resultats-Anzeige wieder ausblenden.
Um die Datensätze nach bestimmten Bedingungen zu filtern, können Kriterien eingegebene werden (Siehe Abfrageentwurf "Kriterium")- «6717» filtert PLZ, so dass nur Datensätze mit PLZ=6717 angezeigt werden.
- «'Meier'» filtert Nachname nach Meier.
- «Wie 'Me?er'» Das ? wirkt als Wildcard (ein Buchstabe kann beliebig sein). Damit würde man Meier und Meyer finden.
- «Wie 'Me*er'» Der * wirkt als Wildcard (mehrere Buchstaben können beliebig sein). Damit würde man Meier, Meyer aber z.B. auch Meiser finden.
- ODER-Verknüpfung von Kriterien: Unter Kriterium bzw. der darunterliegenden Zeile "oder" kann man mehrere Kriterien erfassen, die dann ODER-Verknüpft sind.
- UND-Verknüpfung von Kriterien: Attribut zweimal auswählen und mit Kriterien versehen.
Zum Beispiel: PLZ mit Kriterium «>8000» und daneben PLZ mit Kriterium «<9000»
würde alle PLZ anzeigen die zwischen 8000 und 9000 liegen.
Dasselbe kann auch erreicht werden, wenn man PLZ nur einmal einträgt und als Kriterium folgendes angibt: «>8000 UND <9000» - Kriterium: > #01.01.2010# zeigt jedes Datum nach dem 1.1.2010 an.
- Feld MONTH( [Geburtsdatum] ) zeigt nur den Monat des Geburtsdatums an.
- Feld DATEDIFF( 'dd', [Geburtsdatum], '1980-01-01' ) zeigt die Differenz in Anzahl Tagen vom 1.1.1980.
- Feld CONCAT( 'Frau ' , [Nachname] ) zeigt in dieser Spalte das Attribut Nachname mit einem davorgestellten Frau an. Bsp.: Frau Meier
(CONCAT ist die Abkürzung für CONCATENATE was VERKETTET bedeutet.) - Weitere Möglichkeiten zur Filterung entnehme man dem LibreOffice Base Manual.
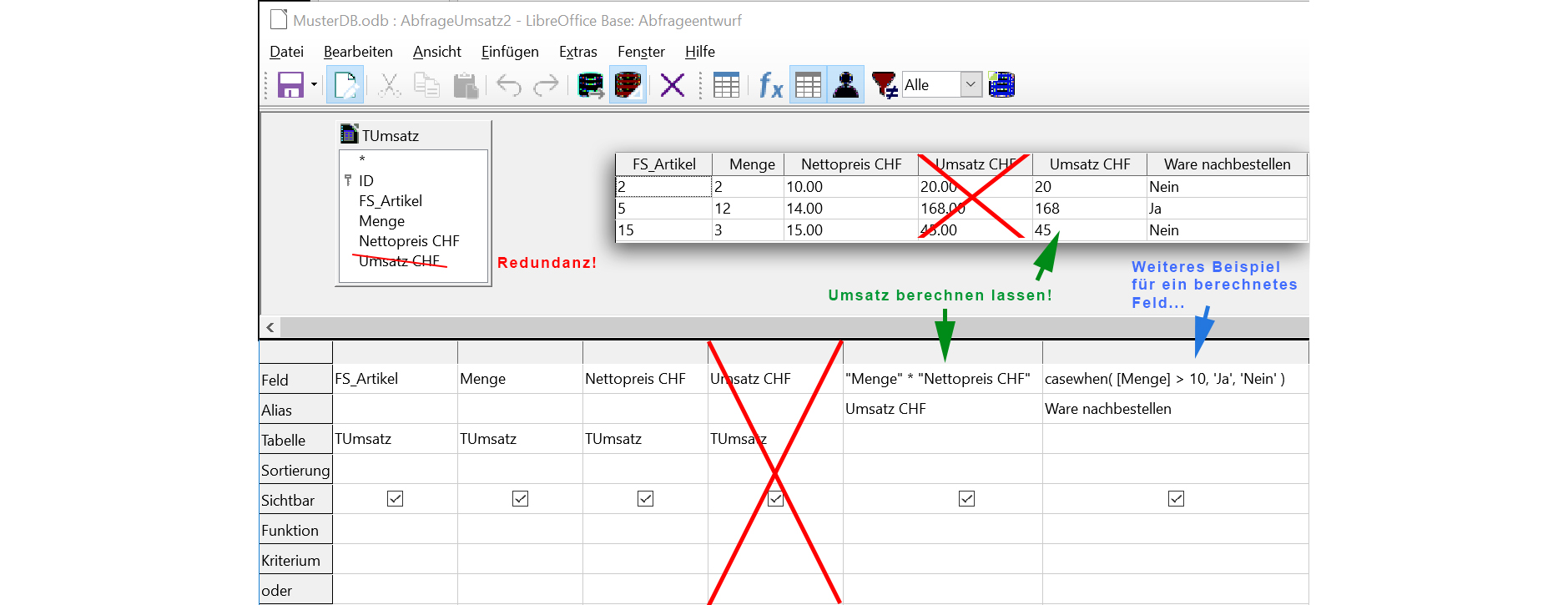
Berechnete Attribute
Grundsätzlich sollten in Datenbanken keine Werte abgespeichert werden, die errechnet werden können (Redundanz). Somit ist die Tabelle "TUmsatz" nicht korrekt, weil mit dem Attribut "Umsatz CHF" genau dies getan wird. Mittels Abfragen, können wir aber eine solche Spalte "Umsatz CHF" definieren. Der Vorteil ist, dass dieser Werte bei jedem Aufruf der Abfrage neu berechnet wird und somit immer aktuell ist.
Aggregatsfunktionen
Diesen sind wir beim Thema Statistik bereits einmal begegnet. Aggregatsfunktionen sind aber auch hier möglich. Wichtig ist die Reihenfoge und Auswahl der Attribute. Es ist also wesentlich, ob man bei dem Beispiel unten das Attribut "ID_Rechnung" mit aufnehmen will und dann die Summe aller Positionen einer Rechnung erhält oder ob dieses Attribut weglassen wird und man dann die Summe der Umsätze der einzelnen Personen bekommt.
 ∇ AUFGABEN
∇ AUFGABEN
∇ LÖSUNGEN
5.2 Formulare in LibreOffice-Base
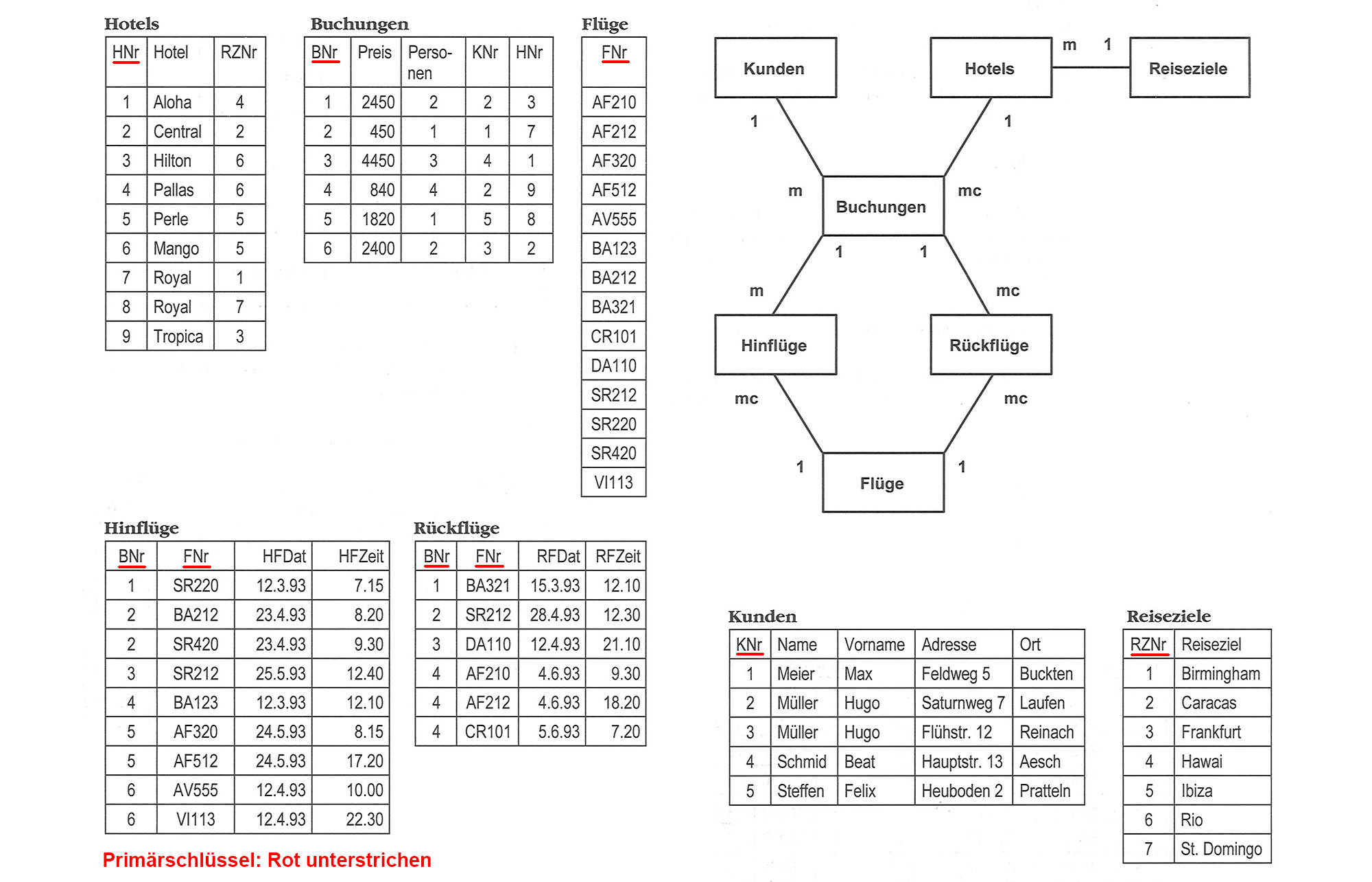
Zum Nachvollziehen und Ergänzen steht diese OpenOfficeBase-Datenbank hier zur Verfügung: FormularBsp.odb Das verwendete Fallbeispiel ist eine Personen-Kontrollschild-Fahrzeug-Verwaltung, also eine mc-mc Beziehung Person zu Fahrzeug, die eine Zwischentabelle Kontrollschild erforderlich macht. Dazu das ERD:

Gebundenes Formular
Ein gebundenes Formular ist ein Datenbankobjekt, mit dem man eine Benutzeroberfläche für eine Datenbankanwendung erstellen kann. Es wird direkt mit einer Datenquelle verbunden, z.B. mit einer Tabelle oder Abfrage, und zum Eingeben, Bearbeiten oder Anzeigen von Daten aus einer Datenquelle verwendet.
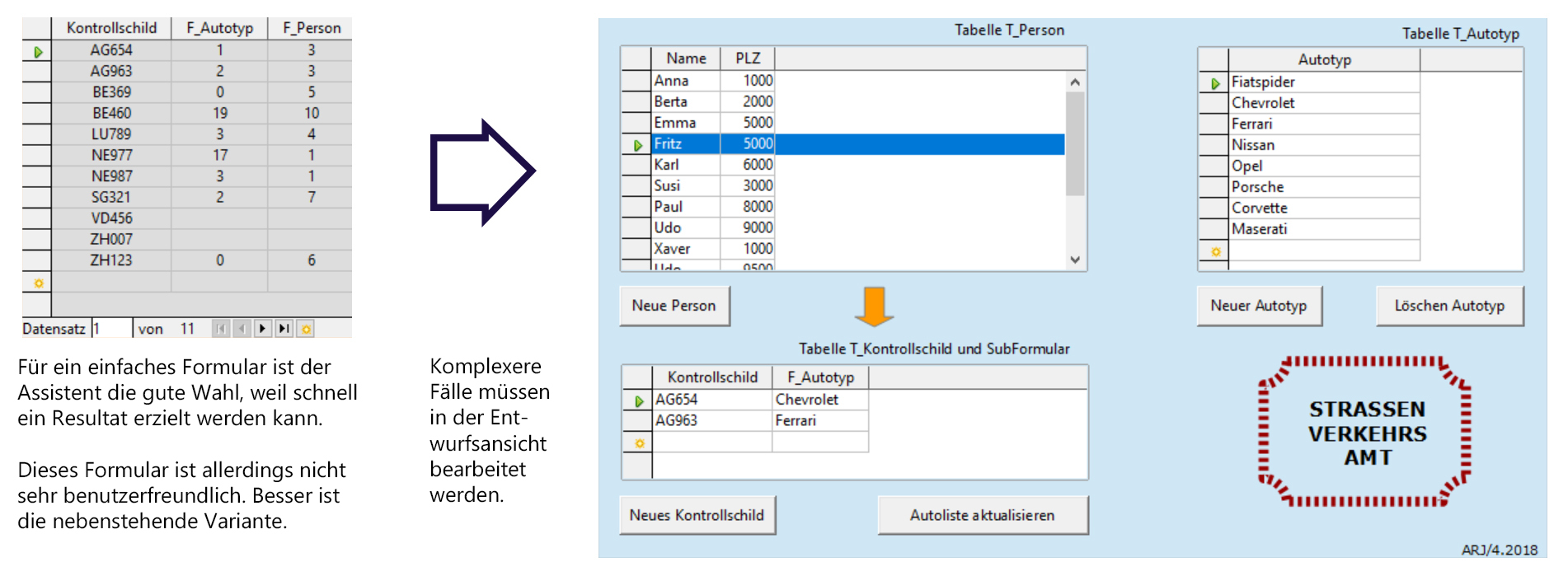
Formular mit Assistenten oder in der Entwurfsansicht erstellen
Um in OpenOfficeBase Formulare zu erstellen, wechselt man zuerst in das Datenbank-Fenster (Linkes Fenster) und wählt dort «Formulare». Nun hat man zwei Möglichekeiten, sein Formular zu erstellen:
- Formular in Entwurfsansicht erstellen...
- Formular unter Verwendung des Assistenten erstellen...
 Hinweis: Das "einfache" Formular (Bild links) findet man in der OpenOfficeBase-DB «FormularBsp.odb» unter Formulare «F1_Liste».
Das komplexere Formular mit Subformular (Bild rechts) findet man in der OpenOfficeBase-DB «FormularBsp.odb» unter Formulare «F5_Subform».
Hinweis: Das "einfache" Formular (Bild links) findet man in der OpenOfficeBase-DB «FormularBsp.odb» unter Formulare «F1_Liste».
Das komplexere Formular mit Subformular (Bild rechts) findet man in der OpenOfficeBase-DB «FormularBsp.odb» unter Formulare «F5_Subform».
Die Datenbank-Eingabefelder (Formulare und Subformulare) können auf verschiedene Arten angelegt werden:- In Spalten - Beschriftungen links oder oben
- Als Datenblatt
- In Blöcken - Beschriftungen oben

Formularvariante "Datenblatt"
Personen-Kontrollschild-Fahrzeug-Verwaltung als Datenblatt: So soll es am Schluss aussehen:
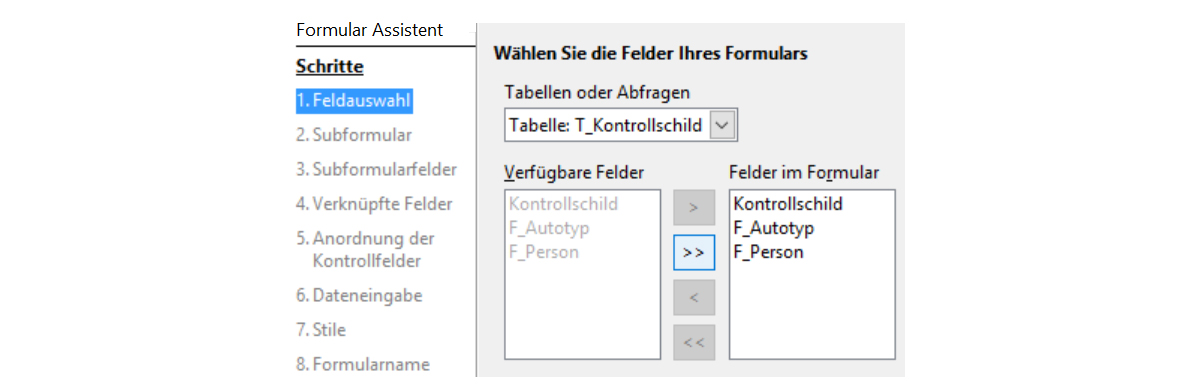
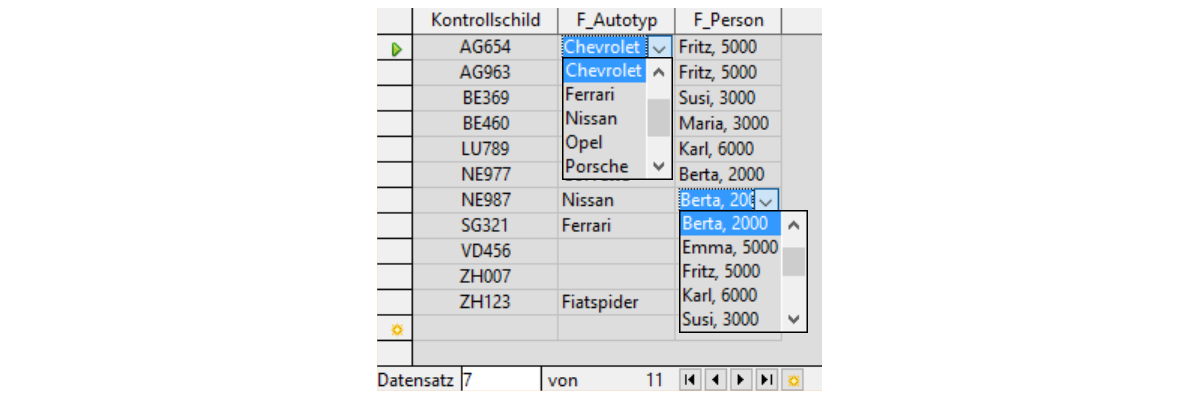 Das Vorgehen: Der erste Formularentwurf wird mit dem Assistenten erstellt. Nur der «Feldauswahl» muss man besondere Beachtung schenken.
Die weiteren Schritte können wie von OpenOfficeBase vorgeschlagen übernommen und allenfalls später im Entwurfsmodus angepasst werden.
Das Vorgehen: Der erste Formularentwurf wird mit dem Assistenten erstellt. Nur der «Feldauswahl» muss man besondere Beachtung schenken.
Die weiteren Schritte können wie von OpenOfficeBase vorgeschlagen übernommen und allenfalls später im Entwurfsmodus angepasst werden.
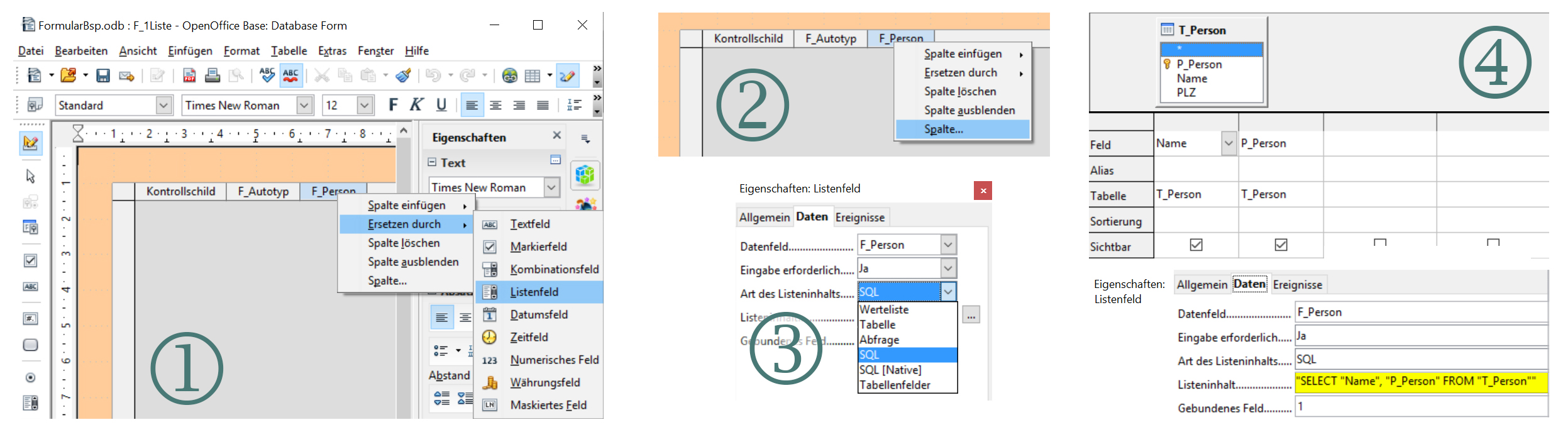
 Nachdem man das Formular mit dem Assistenten erstellt hat, wird es nun im Bearbeitungsmodus (=Entwurfsansicht) angepasst. Dazu das Formular anwählen, danach Rechtsklick → Bearbeiten.
Nachdem man das Formular mit dem Assistenten erstellt hat, wird es nun im Bearbeitungsmodus (=Entwurfsansicht) angepasst. Dazu das Formular anwählen, danach Rechtsklick → Bearbeiten.
- Spalte «F_Person» (=Fremdschlüssel Person) wählen und Rechtsklick, danach «Ersetzen durch» und «Listenfeld».
- Die Eigenschaften der Spalte ändern durch Rechtsklick auf «F_Person» und «Spalte...».
- In den «Eigenschaften Listenfeld» die Datenquelle «Daten» auf «SQL» ändern. Damit soll erreicht werden, dass anstatt dem Fremdschlüssel «F_Person» der Name der betreffenden Person angezeigt wird. Dies erfolgt über eine Abfrage aus der Tabelle «T_Person».
- Nun muss noch die Datenquelle definiert werden. Dazu in den «Eigenschaften Listenfeld» den «Listeninhalt» anpassen > Den Button mit den drei Pünktchen anwählen und es öffnet sich der Abfrageassistent. Bei «Tabelle oder Abfrage hinzufügen» die Tabelle «T_Person» hinzufügen und den Dialog schliessen.
- Im oberen Teil des Abfrageassistenten ist nun die Tabelle «T_Person» aufgeführt. In dieser nacheinander die Felder «Name» und «P_Person» anklicken. Die Attribute erscheinen nun im unteren Teil des Abfrageassistenten. Die Kolonne ganz rechts muss das Attribut sein, das in die Tabelle «T_Kontrollschild» geschrieben wird, in unserem Fall der Fremdschlüssel «F_Person».
 Hinweis: Dieses Datenblatt-Formular findet man in der OpenOfficeBase-DB «FormularBsp.odb» unter Formulare «F2_ListeListe».
Hinweis: Dieses Datenblatt-Formular findet man in der OpenOfficeBase-DB «FormularBsp.odb» unter Formulare «F2_ListeListe».
An dieser Stelle eine kleine Ergänzung:
Will man zusätzlich zum Personennamen «Name» auch noch das weitere Attribut «PLZ» anzeigen, muss wie folgt vorgegangen werden:- Im Abfrageassistenten zusätzlich das Attribut «PLZ» anwählen
- Als «Listeninhalt» wird nun das folgende SQL-Kommando angezeigt:
SELECT "Name", "PLZ", "P_Person" FROM "T_Person" - Da im Datenblatt nur eine Kolonne zur Verfügung steht, müssen die beiden Attribute «Name» und «PLZ» im SQL-Kommando wie folgt verknüpft werden:
SELECT "Name"||', '|| "PLZ", "P_Person" FROM "T_Person"
 Hinweis: Dieses Datenblatt-Formular findet man in der OpenOfficeBase-DB «FormularBsp.odb» unter Formulare «F3_ListeListe».
Hinweis: Dieses Datenblatt-Formular findet man in der OpenOfficeBase-DB «FormularBsp.odb» unter Formulare «F3_ListeListe».
Aufgabe: Ersetzen sie nun in der OpenOfficeBase-DB «FormularBsp.odb» im Formular «F3_ListeListe» den Fremdschlüssel «F_Autotyp» durch die Fahrzeugbezeichnung «Bezeichnung», wiederum als Abfrage aus der Tabelle «T_Autotyp».Formularvariante "Subformular"
Personen-Kontrollschild-Fahrzeug-Verwaltung mit Subformular: Die ist eine Alternative zu dem Formular als Datenblatt und so soll es am Schluss aussehen:
Das Vorgehen: Der erste Formularentwurf wird wiederum mit dem Assistenten erstellt. Die Schritte werden in der folgenden Abbildung gezeigt: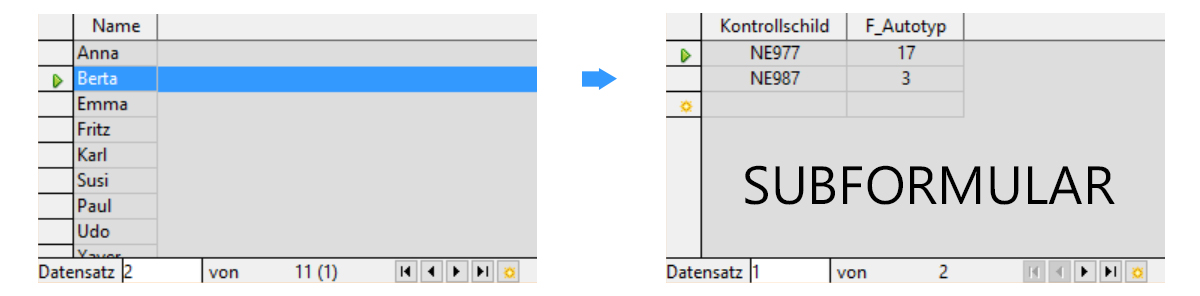
 Hinweis: Dieses Formular mit Subformular findet man in der OpenOfficeBase-DB «FormularBsp.odb» unter Formulare «F4_Subform».
Hinweis: Dieses Formular mit Subformular findet man in der OpenOfficeBase-DB «FormularBsp.odb» unter Formulare «F4_Subform».
Bemerkung: «Subformular basiert auf bestehender Beziehung» bedeutet, dass die Beziehungen zwischen den Tabellen (siehe Topmenu «Extras / Beziehungen») richtig erstellt wurden.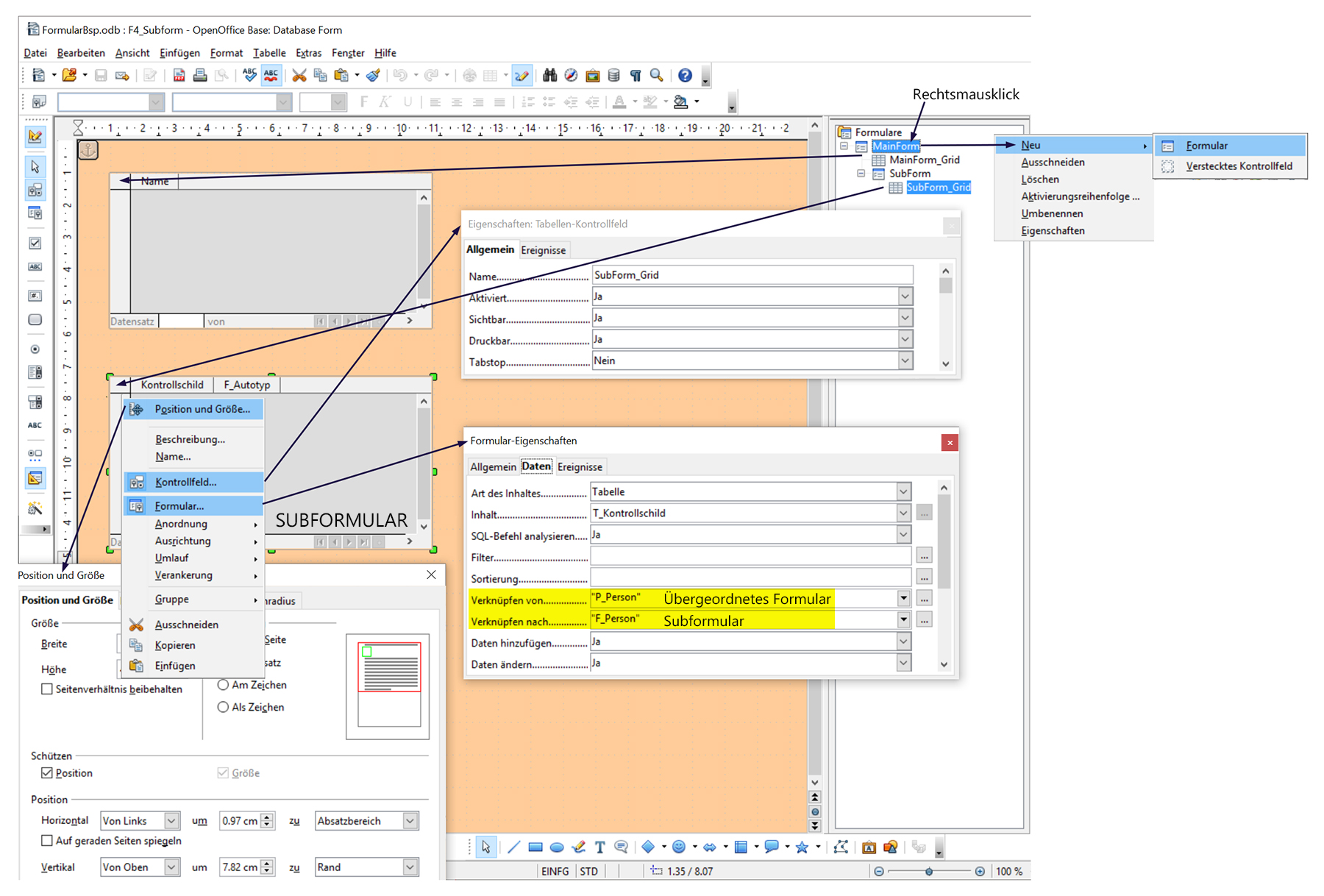 Aufgabe: Ersetzen sie nun in der OpenOfficeBase-DB «FormularBsp.odb» im Formular «F4_Subform» den Fremdschlüssel «F_Autotyp»
durch die Fahrzeugbezeichnung «Bezeichnung», wiederum als Abfrage aus der Tabelle «T_Autotyp».
Aufgabe: Ersetzen sie nun in der OpenOfficeBase-DB «FormularBsp.odb» im Formular «F4_Subform» den Fremdschlüssel «F_Autotyp»
durch die Fahrzeugbezeichnung «Bezeichnung», wiederum als Abfrage aus der Tabelle «T_Autotyp».
Soll nun auch noch die Tabelle «T_Autotyp» bearbeitet werden können, muss dafür ein weiteres Formular erstellt werden. Wie das etwa aussehen könnte, zeigt die OpenOfficeBase-DB «FormularBsp.odb» mit dem Formular «F5_Subform».Tipps zu Formulare
Folgende Symbolleisten sollten im Fenster des Bearbeitungsmodus verfügbar sein (Wählbar im Topmenü unter Ansicht/Symbolleisten):
- Formular-Steuerelemente (Beinhaltet z.B. Schaltflächen, Listen- und Kombinationsfelder etc.)
- Formular-Navigator (Wichtig für die Übersicht Formular/Unterfomular und entsprechende Elemente)
- Formular-Entwurf (Enthält z.B. den Umschaltknopf Entwurfsmodus an/aus und den Knopf für den Formular-Navigator)
- Zeichnung (Enthält grafische Formen und ein Textwerkzeug)
- Der Formular-Navigator ist wichtigstes Instrument zum Überprüfen der Formularstruktur.
- Die Formulare/Unterformulare sind im Formular-Navigator hierarchisch angeordnet.
- Soll in einem Formular ein Unterformular erstellt werden, muss im Formular-Navigator das entsprechende überzuordnende Formular mit Rechtsmausklick selektiert werden. Danach Neu/Formular wählen. Durch Einrücken des neu erstellten Unterformulars wird angezeigt, dass dies hierarchisch unter dem bereits bestehenden Formular angeordnet ist.
- Das Formular (bzw. Unterformular) dient lediglich als Datenquelle. Zu erkennen durch das Selektieren des Formulars mit Rechtsmausklick und danach Eigenschaften wählen. Bei dem nun sich öffnenden Formular-Eigenschaftsfenster interessiert vor allem die Datenherkunft unter Daten/Inhalt.
- Das Formular kann nicht für Eingaben verwendet werden. Dazu muss man dem Formular nun Eingabefelder wie Listen- und Kombinationsfelder etc. einverleiben. Durch Rechtsklick auf das entsprechende Feld können unter Kontrollfeld wichtige Eigenschaften ergänzt oder überprüft werden wie z.B. Daten/Datenfeld.
- Auch bei den Schaltflächen muss beachtet werden, welchem Formular diese man hinzufügt.
- Als Unterformular empfiehlt sich die Verwendung eines Grids. (Tabellen-Kontrollfeld). Dies kann man bei den Formular-Steuerelementen finden. Aus Platzgründen werden einige Felder, mitunter auch das Tabellen-Kontrollfeld nicht direkt angezeigt. Darum zuerst das Icon «Weitere Steuerelemente» anklicken (Icon mit zwei Symbolen und drei Punkten darunter)
- Ein Tabellen-Kontrollfeld kann mehrere Spalten mit z.B. Listenfelder enthalten.
∇ AUFGABEN
6. Test und Dokumentation
Was unterscheidet unstrukturiertes «Ausprobieren» von seriösem, formalen «Testen»? Nach der Lektüre dieses Abschnittes sollten sie in der Lage sein, sinnvolle Tests zu definieren, durchzuführen und zu dokumentieren. Was sind die Bestandteile einer zielgerichteten Dokumentation und welche verschiedenen Möglichkeiten und Formen gibt es? Dieser Artikel nennt die verschiedenen Zielgruppen und wie sie für diese eine niveaugerechte Dokumentation erstellen können.
Warum dokumentieren? Der Zweck der Dokumentation besteht darin, das der Anwender das System selbstständig bedienen kann (Benutzerdokumentation) und der Entwickler das System weiter entwickeln, beziehungsweise Fehler suchen und korrigieren kann (Systemdokumentation)- Systemdokumentation
Dazu gehört: Namenskonventionen für Benennung von Objekten, Tabellen, Abfragen etc., ERD, Tabellenbeschreibung, Inlinedokumentation, Kommentare in der Datenbank. - Benutzerdokumentation
Zielgruppenorientierte Anleitung zur Benutzung der Datenbank als z.B. Online-Hilfe. Nützlich sind auch aussagekräftige Fehlermeldungen.
Das Produkt systematisch Testen, indem zuvor Testfälle bestimmt werden und die Testausführung präzise dokumentiert wird:
Ein Testfall beschreibt einen elementaren, funktionalen Softwaretest, der zur Überprüfung einer z.B. in einer Spezifikation zugesicherten Eigenschaft eines Testobjektes dient. Bestandteile der Beschreibung eines Testfalls sind:- Die Vorbedingungen, die vor der Testausführung hergestellt werden müssen
- Die Eingaben/Handlungen, die zur Durchführung des Testfalls notwendig sind
- Die erwarteten Ausgaben/Reaktionen des Testobjektes auf die Eingaben
- Die erwarteten Nachbedingungen, die als Ergebnis der Durchführung des Testfalls erzielt werden
∇ AUFGABEN
∇ LÖSUNGEN